Introducing Gaudio Sing, the Next-Generation Karaoke System
Ever Heard of a Global Audio AI Tech Company Created Karaoke System?
After we, Gaudio Lab, captured worldwide attention with our generative AI 'Fall-E', we're now on the brink of officially launching Gaudio Sing, our cutting-edge karaoke system.
You might be wondering, "Karaoke?"
Well, the concept behind Gaudio Sing is actually quite relatable—it all started with a simple desire that many of us have had: singing duets with our favorite artists or belting out tunes to original backing tracks.
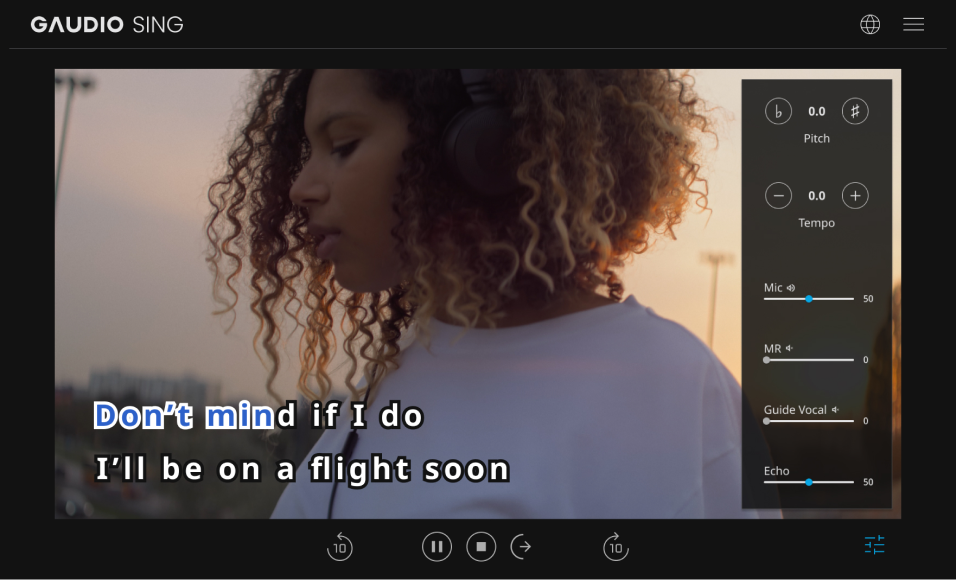
At the heart of our innovation lie our core AI technologies. GSEP (Gaudio source SEParation) allows real-time vocal removal, while GTS (Gaudio Text Sync) synchronizes lyrics—an AI marvel adored by music streaming services worldwide. Together, these technologies give birth to a karaoke feature where you can sing along to original tracks as if by magic.
But that's not all; our expertise in signal processing and AI enhances features like sound filters (Reverb, Echo), drum/beat separation for pitch and speed adjustment, and detailed scoring capabilities. What may seem like a simple karaoke setup is, in fact, a sophisticated blend of state-of-the-art audio technologies.
Gaudio Sing embodies our commitment to revolutionizing audio experiences, perfectly aligning with our mission to deliver the pinnacle of sound quality to users worldwide.
"Revolutionizing Karaoke ‘Spaces’ with Innovative Technology"
Traditional karaoke spaces are currently challenged by various karaoke apps and software. These are available on a wide range of platforms, from smartphones to smart TVs, but they still haven't become widely popular. A comfortable 'space' to sing is crucial for users, yet existing apps often overlook the importance of a new user experience and a comfortable singing environment.
We believe in the importance of karaoke spaces and the experiences within them. Providing an exceptional sound experience in a karaoke space is paramount. Our goal isn't merely to launch new karaoke software but to revolutionize the existing karaoke experience with Gaudio Lab's technology.
With Gaudio Sing, in a karaoke room, users can select songs via their smartphones and enjoy features like the automatic creation of personalized playlists. We also offer fun elements that allow users to assess their singing skills on a national level, enabling competition and collaboration with others. Since our system is implemented purely through software without traditional accompaniment machines, we can use augmented reality (AR) technology to provide an even more immersive karaoke room experience.
We aim to transform traditional karaoke rooms into cultural spaces where families, friends, and individuals can relax and enjoy themselves. This experience, which can't be replicated by mobile apps or smart TVs, is unique to physical spaces.

Starting in the Birthplace of Karaoke: Japan
Our karaoke culture originated from Japan, the birthplace of karaoke, but it has evolved differently in Korea. In Japan, it's common to see long lines forming outside popular karaoke facilities early in the morning, a stark contrast to Korea's karaoke rooms that typically operate only at night. Japanese karaoke isn't just about singing; it's a "multi-room" concept where people can gather to sing, practice instruments alone, watch idol performances, or even wait for friends as an alternative to a café.
With Gaudio Lab's core technology, GSA (Gaudio Spatial Audio), users can enjoy optimal sound effects that make them feel like they're in a concert hall. Additionally, GSEP allows for the separation of vocals and various instruments, enabling users to practice guitar solos to original tracks in karaoke rooms.
The COVID-19 pandemic heavily impacted Japan's karaoke market, but it still maintains a significant size of 2.8 billion dollars and is quickly recovering to pre-pandemic levels. The market is dominated by two hardware manufacturers and over ten karaoke chain operators who use this hardware, leading to a closed structure that has slowed digitalization. This market size, the positive image of karaoke culture, and the outdated user experience due to the monopolistic structure present a unique opportunity for us. Our collaboration with a key player in Japan's karaoke industry has affirmed that Japan is the perfect place to bring our vision of Gaudio Sing to life.
In Japan, karaoke goes beyond mere entertainment; it's a crucial cultural element that fosters social bonds. People use karaoke to relieve stress and enjoy time with friends and family. Gaudio Lab aims to leverage this positive image of karaoke and introduce innovative technology to carve out a new market within Japan. Success in Japan will also positively impact our expansion into other countries.

In Conclusion: Music - The Universal Language
Music possesses a powerful ability to unite people across languages and cultures. The phrase "Music is the universal language" exists for a reason—it's beloved worldwide.
At the heart of this culture lies karaoke. We believe that Gaudio Sing, offering this universal joy in a new way, will bring positive changes not only in Japan but also in our own country.
Thank you for joining us on this journey into the future of karaoke.
Stay tuned as we revolutionize the way we sing, connect, and celebrate through the power of music.


Our audio technologies support various devices and platforms.
