Exploring ICML 2024: Latest Advances in AI and Audio Research
Introduction
Hello again, it’s Kaya back with more updates!
As a researcher focused on audio AI at Gaudio Lab, I often get the chance to attend various conferences. You might remember my recent post on ICASSP 2024 & Gaudio Night.
This time, I’m excited to share my experience attending the ICML (International Conference on Machine Learning) 2024, which was held in beautiful Vienna, Austria.
ICML is one of the most prominent AI conferences in the world, along with ICLR and NeurIPS, and Gaudio Lab makes it a point to attend every year. It’s an incredible opportunity for researchers like me to connect with others in the field and discover the latest breakthroughs.
Unlike my last post, which focused on the event atmosphere, this one will dive into the innovative ideas and insights I gained from ICML 2024!

Highlights from ICML 2024
Spotlighted Papers
Let’s start with a few standout research papers I encountered. The first one that caught my eye was "Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution." This study introduces a novel approach to handling discrete data, showcasing a method called SEDD that outperforms existing SOTA models like GPT-2 in the natural language processing field. This research significantly broadens the applicability of diffusion models and has made a notable impact in the AI community.
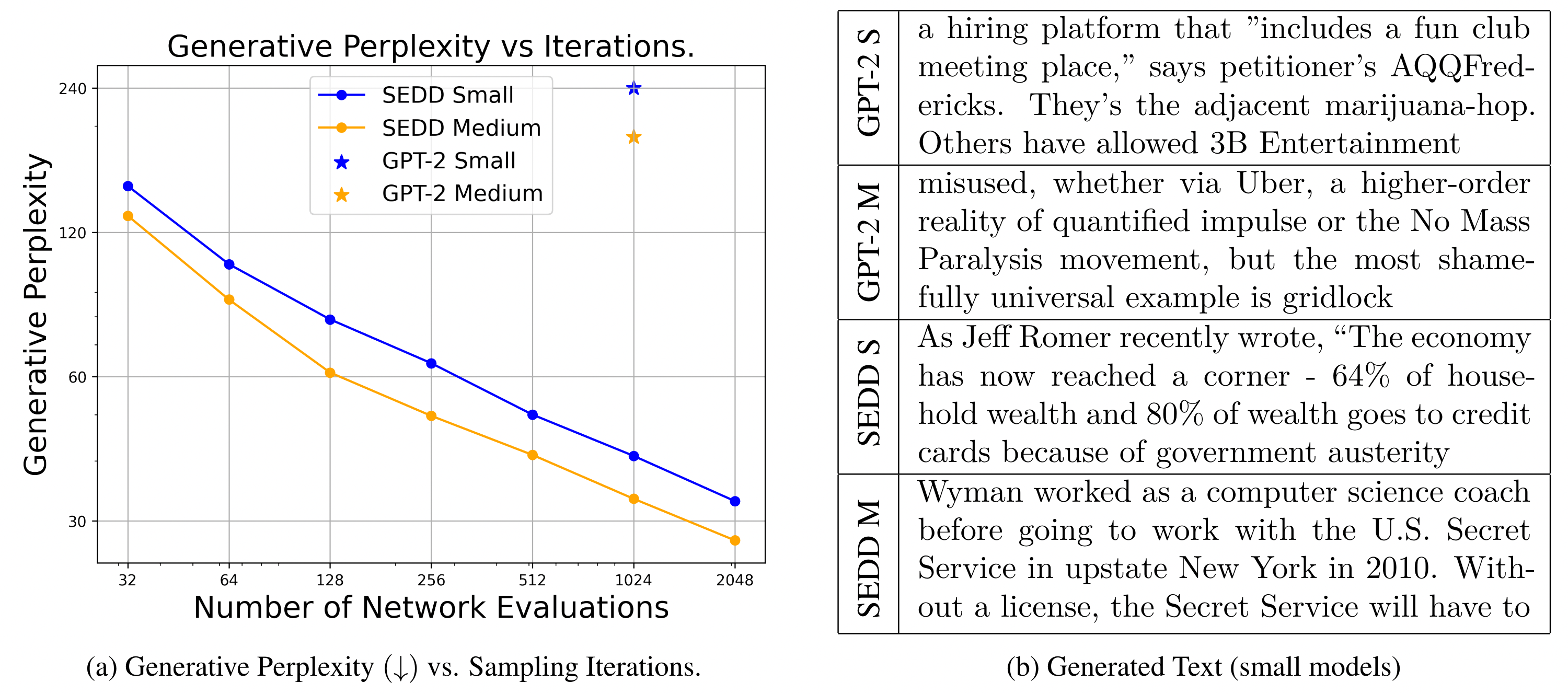
Lou, Aaron, Chenlin Meng, and Stefano Ermon. "Discrete Diffusion Language Modeling by Estimating the Ratios of the Data Distribution."
Another intriguing study was titled "Debating with More Persuasive LLMs Leads to More Truthful Answers." This paper presents experimental evidence that AI models can enhance their accuracy through debates—a concept that once seemed confined to the realm of imagination. This research could play a crucial role in addressing issues with misinformation in models like ChatGPT.
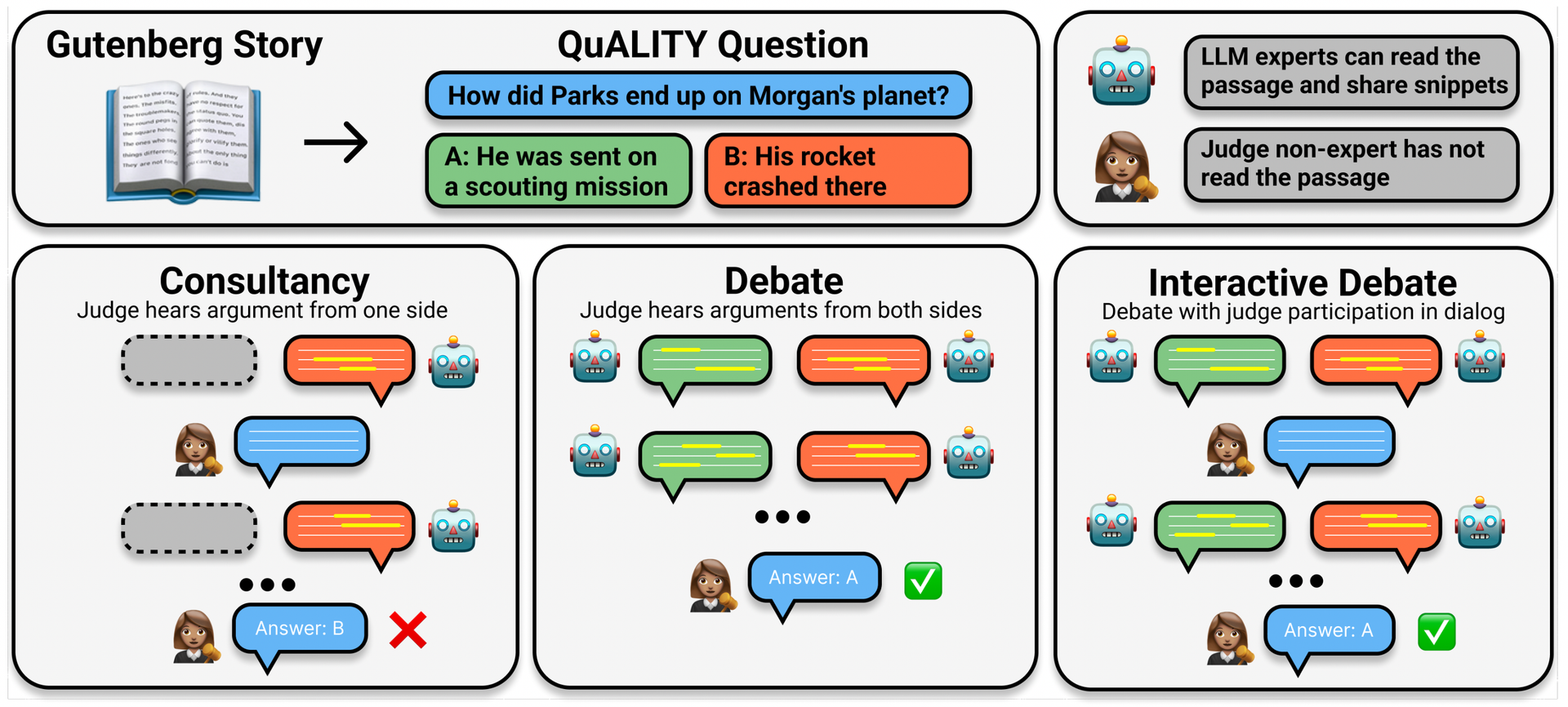
Khan, Akbir, et al. "Debating with More Persuasive LLMs Leads to More Truthful Answers."
The Introduction of “Position” Papers
A new category of papers made its debut at this year’s ICML: ✨Position✨ papers. These papers don’t necessarily propose new models or ideas; instead, they challenge current academic norms and provoke deep reflection.
One particularly compelling paper was titled "Position: Measure Dataset Diversity, Don’t Just Claim It." This study argues that simply asserting dataset diversity isn’t enough. The authors analyzed 135 image and text datasets to offer a fresh perspective on the topic, reminding us as AI researchers to deeply consider the fairness and inclusiveness of datasets.
Trends in Audio Research
ICML 2024 also featured a number of exciting papers on audio AI.
The current trend in this field is a focus on more sophisticated generative models, which is evident across areas from music generation to general-purpose audio synthesis.
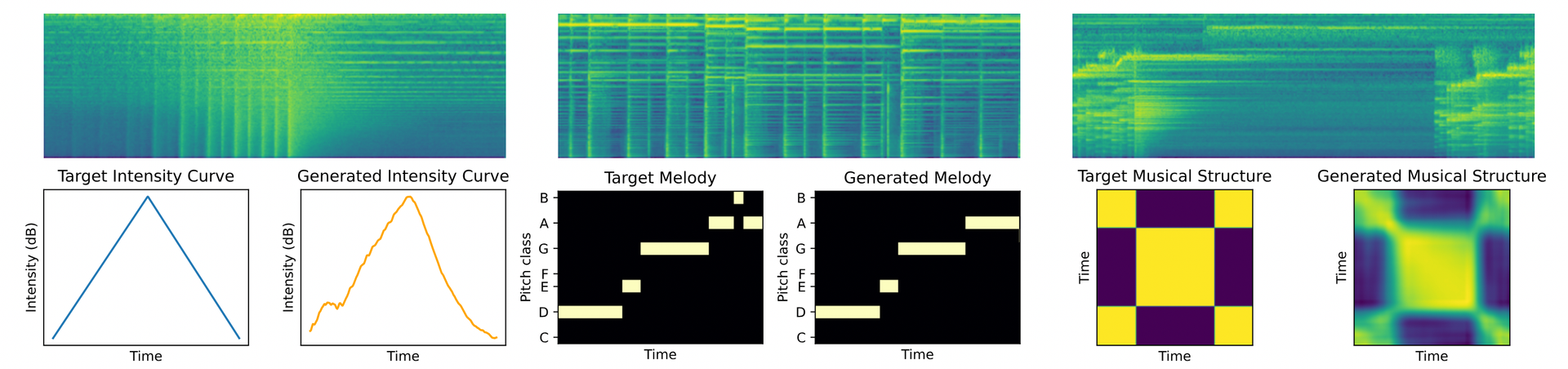
Novack, Zachary, et al. "Ditto: Diffusion inference-time t-optimization for music generation."
Additionally, Video-to-Audio Generation has emerged as a hot topic. With tools like OpenAI’s “Sora” pushing the boundaries of video generation, the creation of matching audio for these videos has become a critical research area. Google proposed a model called "VideoPoet" that generates both video and audio simultaneously, while Adobe introduced "Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity," focusing on syncing sound effects with video actions.
These developments naturally reminded me of Gaudio Lab’s own sound effects generation model, FALL-E. It’s a technology that even caught the attention of Microsoft’s CEO, Satya Nadella, at CES. A few months ago, we demonstrated how FALL-E could generate sound effects perfectly synchronized with Sora videos. Seeing these trends at ICML reinforced my pride in how quickly Gaudio Lab is catching on to industry trends and reaffirmed our team’s research direction.😎
Conclusion
In this post, I’ve shared some of the diverse trends and fascinating research from ICML 2024.
I was so engaged in exploring all the new studies that I found myself running around the conference hall to keep up with everything! 🏃♀️

One particularly fun experience was a poster session where researchers were given questions about large language models (LLMs) and then encouraged to debate, turning the session into a lively and spontaneous event.
Attending ICML 2024 and absorbing all the new trends and research has left me feeling inspired and ready to return to Korea to continue developing smarter AI models. I’m excited to apply the knowledge and inspiration I gained from the conference.
Hopefully, at the next conference, we’ll see Gaudio Lab’s research featured as a spotlighted paper! 💪 Until then, this wraps up my ICML 2024 recap. 😁


Our audio technologies support various devices and platforms.
