My Score Is... Introducing the MUSHRA Listening Test
Hello, I'm Ted, and since the start of Gaudio Lab, I've been on board tackling a myriad of tasks.
Recently, we've conducted listening tests to assess the performance of the technology we've developed. Thinking it would be beneficial to have an easily understandable explanation of this listening test, I've decided to jot down a few notes.
Just as when you visit a hospital or watch a medical drama, you might occasionally be asked this question: "On a scale from 0, representing no pain at all, to 10, denoting the most intense pain imaginable, how would you rate your pain right now?" While writing this article, I learned that such a question is referred to as an NRS (Numeric Rating Scale). Since the experience of pain is subjective, the NRS helps to simplify and quantify it in an easily understandable manner, thus effectively aiding in pain management and treatment. It might feel odd discussing medical terminology in an audio-related blog. 🙂
Can Sound Be Quantified? - The MUSHRA Listening Test
So, what about sound?
When there are two sounds, how can we evaluate which one is better?
In the audio field, there have been numerous attempts to develop technology that can objectively evaluate sound without human hearing. Unfortunately, such technology has not yet been perfected. In other words, we have not reached the point where a machine can analyze sound and declare, "This sound scores an 80, human.🤖"
Instead, methodologies that involve listening to and evaluating sounds have been widely used for some time. For example, there are MUSHRA (Multiple Stimuli with Hidden Reference and Anchor), ABX, and MOS (Mean Opinion Score), among others. Today, I'd like to introduce the MUSHRA evaluation method, which is particularly tailored to assess the subtle differences between high-quality audio samples.
MUSHRA stands for the Method of Assessment of audio systemS Handling of Degraded Reference Signals. It is primarily used to evaluate high-quality audio technologies/systems. Standardized by the International Telecommunication Union (ITU), it is especially useful for assessing the subtle differences between audio samples. The core principle of the MUSHRA evaluation involves presenting several test samples simultaneously and asking participants to compare them, rating each on a scale from 0 to 100.
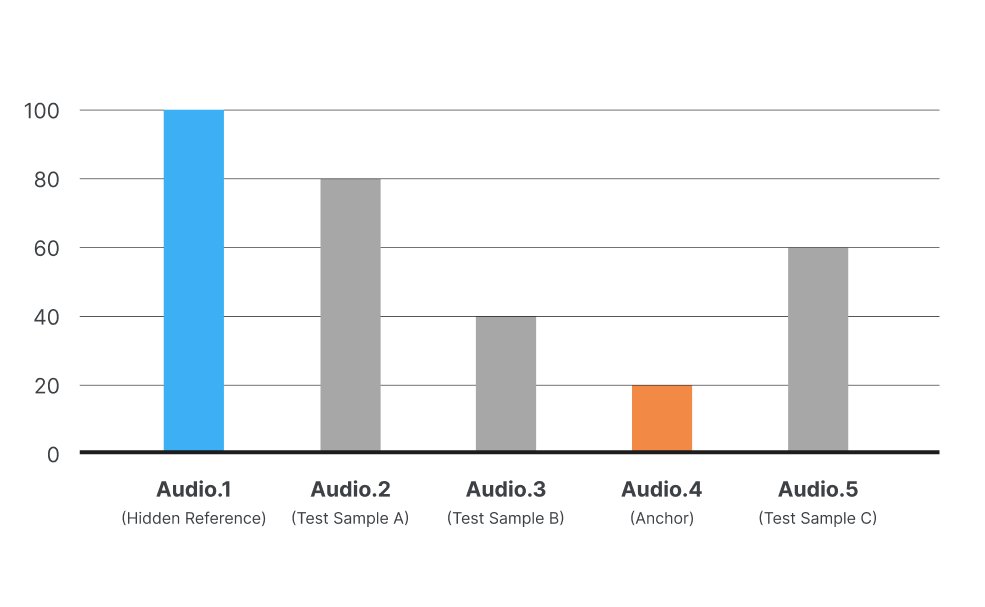
The samples provided include:
-
Hidden Reference: A high-quality version of the original audio track, used as the highest benchmark for participants to compare other samples against. Participants are unaware that this sample serves as the reference.
-
Anchor: Typically, a lower-quality audio sample that acts as the lower benchmark for evaluation. This helps participants have a clearer understanding of the rating scale.
-
Test Samples: Samples generated through various audio systems that are being evaluated.
The Hidden Reference is considered the "correct answer," or 100 points, and the Anchor is set as a low benchmark, roughly equivalent to 20 points. Test Samples are then evaluated on a scale from 0 to 100.
Comparing this to the NRS, if we were to draw parallels, the Hidden Reference could be likened to the most intense pain imaginable, while the Anchor would represent no pain at all. However, unlike the NRS where the no pain mark is set at 0, the Anchor is not set at 0 in MUSHRA evaluations because Test Samples may perform worse than the Anchor. Another distinction from the NRS is that while the most intense pain can vary from person to person, the Hidden Reference is a consistent sound for everyone, making it more objective.
Moreover, MUSHRA includes a post-screening rule to ensure that evaluators do not rate randomly, understand the given instructions well, and have the capacity to sufficiently distinguish between performances. It's quite a systematic approach, isn't it?
We've Tried MUSHRA Listening Test Ourselves.
Understanding this might still be challenging, so let me illustrate with an example from a subjective performance evaluation of the Just Voice SDK, conducted by Gaudio Lab in January.
1) MUSHRA Test Design
The Just Voice SDK is designed for implementation in Mobile, PC, and Embedded systems, offering the capability to eliminate noise in real-time. We aimed to compare its performance with that of Krisp, a noise cancellation technology integrated into Discord, focusing on two main aspects: the effectiveness of noise removal and the clarity of the voice. Both performances were assessed using the MUSHRA method.
The Hidden Reference was recorded in a quiet studio, simulating a typical scenario like a video conference, using various smartphones. The Test Samples were created by adding noise with an SNR of 5dB to the Hidden Reference and then processing these signals with the Just Voice SDK and Krisp SDK for noise removal, respectively, for comparison.
What's interesting is the Anchor. Since the two performances evaluated are different, they necessitated setting different Anchors. For the first performance evaluation, noise removal, the Anchor was set as the signal mixed with noise at an SNR of 5dB before noise removal. For the second performance evaluation, voice clarity, the Anchor was set as the Hidden Reference passed through a 3.5kHz Low-pass filter, leaving only the lower frequency bands - a common method used in voice quality evaluation.
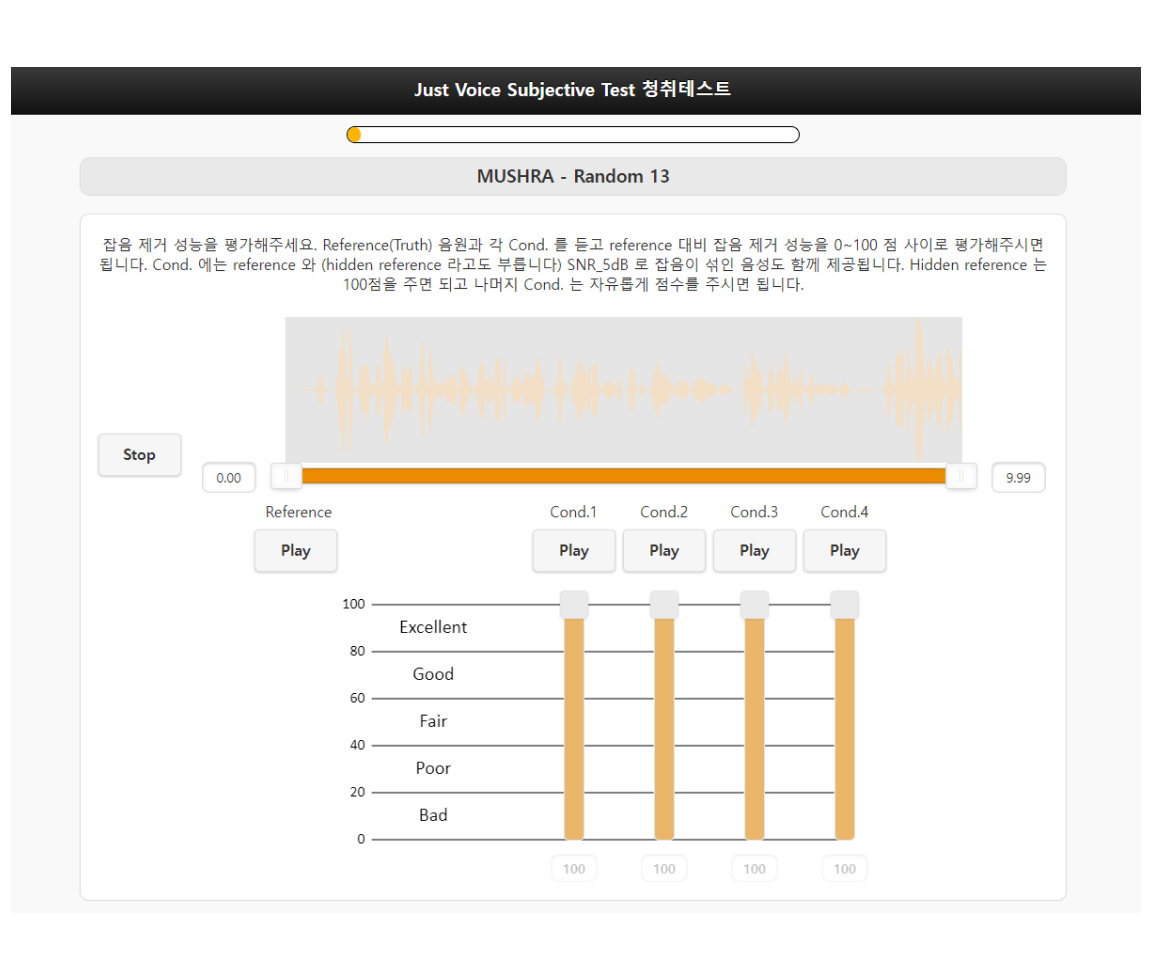
2) MUSHRA Test Procedure
The evaluation was carried out using a tool WebMushra, which features the following UI setup. The Reference plays the Hidden Reference, and Cond. 1 to 4 randomly play the Hidden Reference, Anchor, and Test Samples (Just Voice SDK, Krisp). Evaluators listen to and compare Cond. 1 to 4, attempting to identify the Hidden Reference to award it 100 points, and the Anchor to give it a score around 20 points, a relatively low score. For the remaining two Conditions, they are to assign scores relative to the Reference and Anchor.
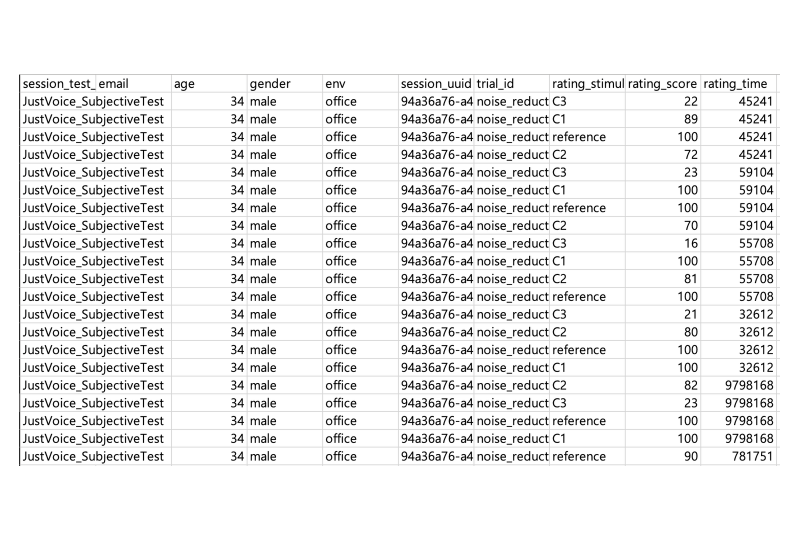
When conducting evaluations with multiple Test Items, the scores assigned by each evaluator for each Condition are recorded in a csv file, as shown in the image below.
How Did the Results Turn Out?
1) Interpreting MUSHRA Test Results
Once all evaluators have completed their assessments, the post-screening rule is applied to exclude any unfit results. Then, the average scores for each Condition, along with their 95% confidence intervals, are plotted for comparison. A 95% confidence interval means there's a 95% probability that the scores given by evaluators fall within a specific range.
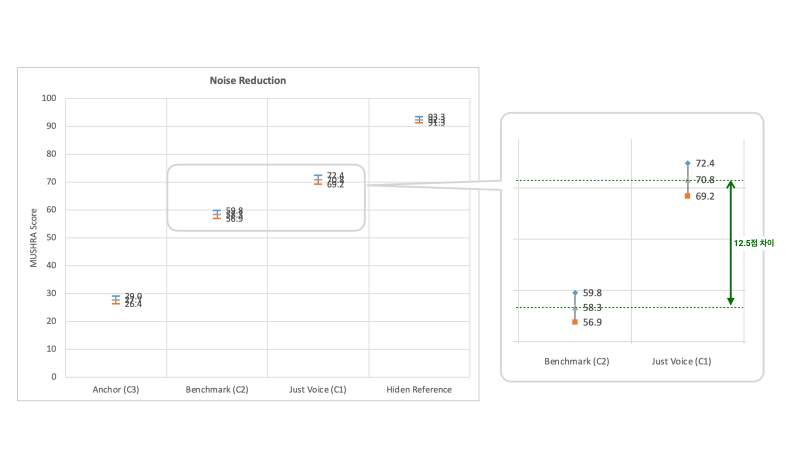
Below are the results for the noise removal performance from our experiment. The grey markers represent the averages, while the blue and orange markers indicate the maximum and minimum of the 95% confidence intervals, respectively. If these confidence intervals do not overlap, it signifies a statistically significant difference in performance between the conditions, meaning they are distinguishable from each other. Moreover, the more evaluators there are, the narrower these confidence intervals become.
2) Noise Removal Evaluation Results
This experiment, with a participation of 66 individuals, was large scale, resulting in quite narrow confidence intervals. Comparing the benchmark (Krisp) with Just Voice, we observe that the confidence intervals do not overlap, and there is a difference of 12.5 points between them. Such a margin clearly indicates a distinguishable performance difference between the two technologies.
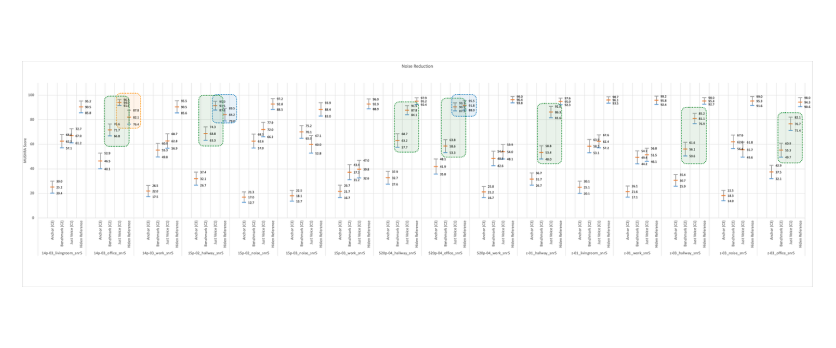
When analyzing the listening test results in detail, it's important to examine the outcomes for each Test item. Just Voice was found to have significantly better noise removal performance than the Benchmark (Krisp) in 7 out of 16 Test items at a 95% significance level (indicated in green).
An interesting observation was that in 3 Test items (14p-03_office, 15p-02_hallway, s20p-04_office), the average scores for Just Voice were higher than those for the Hidden Reference (indicated in blue and orange). This was attributed to the inclusion of noise in the smartphone-recorded References used to simulate real-world environments. Just Voice managed to remove noise more effectively without distorting the voice, resulting in higher scores than the Reference, making it nearly indistinguishable from the Reference in terms of noise removal.
Remarkably, for the 14p-03_office item, Just Voice achieved results that were not only statistically significant at a 95% confidence level but also scored higher than the Reference (indicated in orange), effectively being judged as better than the Reference itself.👍
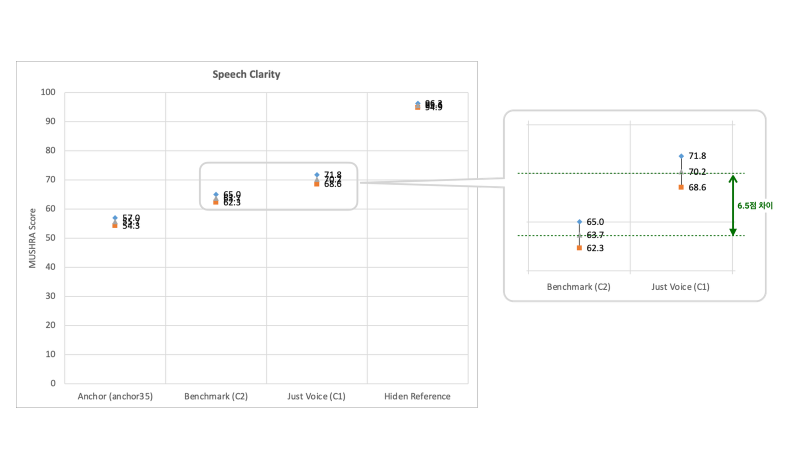
3) Voice Clarity Evaluation Results
For those curious about the voice clarity experiment results, I've attached them below. Using the method described earlier, you can interpret the results directly.😉

Concluding Thoughts
Today, we delved into the MUSHRA, a subjective audio quality evaluation method used to compare the performance of high-quality audio/systems. Evaluating subjective audio quality requires considerable thought and effort, from determining what to use as the Hidden Reference and Anchor, to ensuring the experiment runs smoothly.
Personally, I'm looking forward to the day when AI technology advances to the point where it can say, "This sound scores a 95, human. 🤖" with high precision.
If you're interested in learning more about the MUSHRA methodology or other subjective audio quality evaluation methods like ABX or MOS, please leave a query. I'd be happy to write more on this topic.🙂

Our audio technologies support various devices and platforms.
