Behind the Scenes: Gaudio Lab's B2C App Debut, Just Voice Lite
🎙️ Interviewer’s note
Hi there! I'm Harry, a marketing intern at Gaudio Lab. 😊 We've just released our first B2C app, Just Voice Lite, and our marketing team took a behind-the-scenes look at the team behind the app.
We interviewed Howard, our PO, who came up with the idea for our first B2C service; Joey, an 8-year veteran developer; Jack, who juggles audio SDK and app development; and Steven, the team's trusted app developer.

People involved in the development of Just Voice Lite
We thought we could scale up,
if we could broaden the product
to a general user audience.
Q. What was the reason for GaudioLab, which had been developing B2B audio solutions, to start developing B2C services?
Howard (PO) : I didn't listen to the company. 🙂 I suggested B2C as soon as I joined the company. Just like waiting for the fruit to fall from the tree, with B2B, you have to wait for customers, right? I thought scaling up would be possible if we could broaden the product to target general users.
Q. What were you hoping to accomplish with your first B2C app?
Howard (PO): We weren't sure if we were going to be able to make a ton of money with this, so it was more like, 'Let's start lightly and for free for now.'.
Joey (Dev): Just Voice Lite was more like an app to promote GaudioLab's technology rather than an app for revenue. The idea was to showcase our technology as a B2C product to attract B2B customers.
Jack (Dev) : I think we can put a lot of our SDKs like spatial acoustics, EQ, loudness normalization, etc. into the app now, and it will be possible as we grow the app.
Q. Were there any additional considerations in developing a B2C service compared to a B2B service?
Howard (PO): When you're selling an SDK (Software Development Kit) to an enterprise, even if it's a little difficult to use, you can explain it in the user manual, but it's a different story when you're trying to convince a regular user. If there's any hassle or inconvenience, they'll just delete it. The moment they have to click one more time or change their experience, they'll stop using it.
Joey (Dev): Since we have to use a virtual driver, we thought a lot about how to make sure that users can use the core features of the product smoothly without any obstacles.
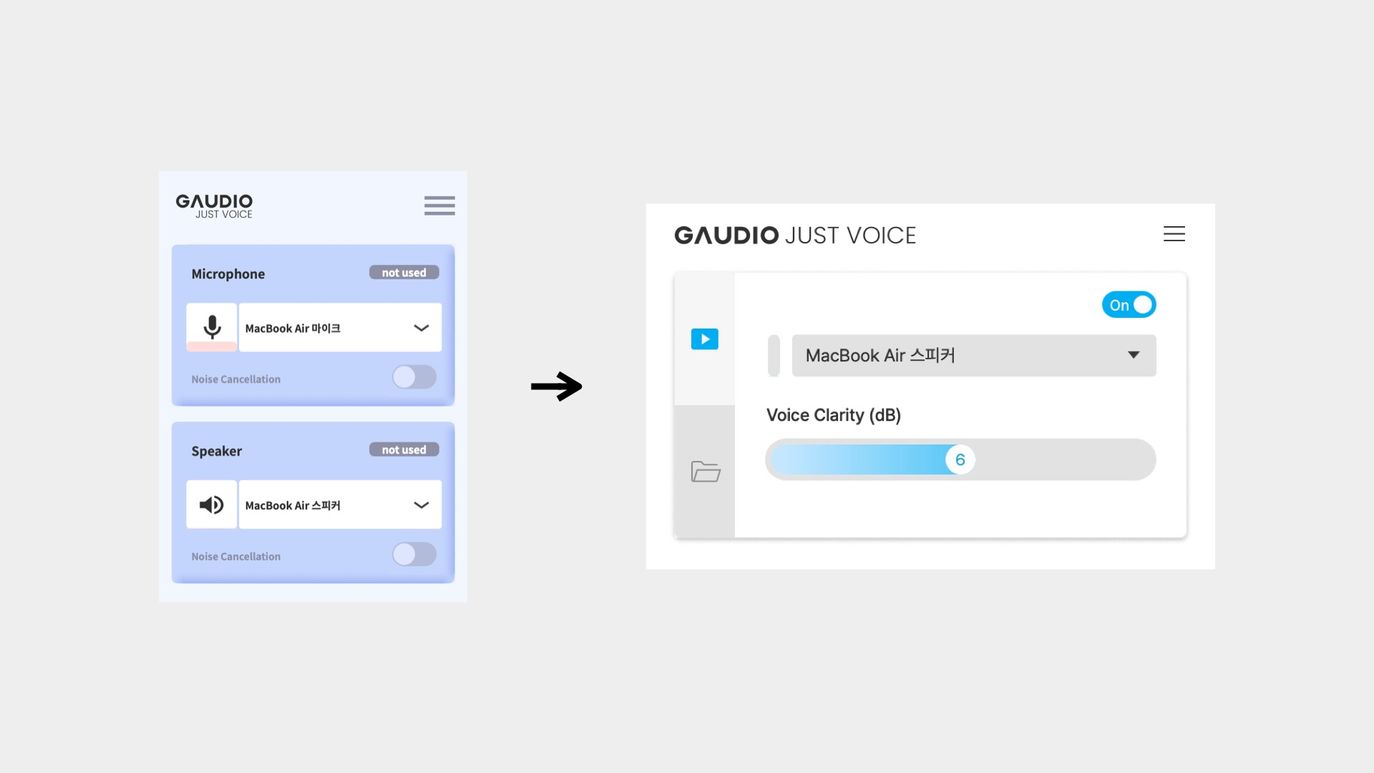
Even with the same technology,
it can be used differently
depending on the user.
Q. Has the development intention changed significantly from existing apps?
Howard (PO) : I wanted to create an app that solves different pain points from existing noise reduction apps. So, we changed the main target from office workers who frequently participate in video conferences to fans who like artists. By slightly changing the shape to an app that boosts voices instead of an app that removes noise, I suggested targeting the content streaming market. For example, when watching a concert video, you can remove surrounding noise and focus on the artist's voice, or when watching a movie, you can make the actor's voice clearer if it's not audible.
Joey (Dev): The same technology can be used differently depending on who's using it, and Howard was really good at spotting this.
Jack (Dev): I liked this perspective. Originally, Just Voice Lite has a feature called GSEP (Gaudio Source Separation), which is 'Denoise.' But now, looking at the application form, it's 'Speech Enhancement.' It seemed impressive to make it look like it's made with different technology.
Joey (Dev) : Yeah, I think Howard did a good job with that. If you explain audio-based technology to a general user, they wouldn't understand the need for it, but we targeted the product to B2C with flexibility, saying, "It makes artists' voices sound better.
Howard (PO): I wrote about it in the blog, but for example, Joey is at Google Meet right now, and he's singing and playing guitar, and if you put noise reduction on it, you can't hear the guitar. When fans of artists watch content, it's not just the voice, it's also the background music, so we thought, "Why not boost voice?
Q. What are the technologies behind Just Voice Lite?
Jack (Dev): Just Voice Lite has an AI technology called GSEP that removes noise. It's SDK'd, and it's the noise removal technology that's been rated as the most effective in listening evaluations. And this noise separation algorithm runs in real-time.
When we brought this technology to the Mac OS app, we put a lot of effort into making the usability of it a seamless experience. And Joey worked with us to make sure that the video sync works well when using Bluetooth on the desktop, so you can watch content seamlessly. In summary, I think Just Voice Lite's strengths are the technology behind the algorithm, the performance of the SDK, and the know-how to make the application seamless.

Apple is very selective
when it comes to
first-time app releases.
Q. It took a while to get through the App Store review, didn't it?
Joey (Dev) : Companies releasing their first apps usually face strict reviews from Apple. That's what they say in the industry. When I asked my friends at other companies, they said that if it's the first app, it's considered good if it passes on the 10th attempt. Some even said they get rejected up to 30 times... 🙂
Harry (Marketer): How long does it usually take to get a review response?
Howard(PO) : It depends on the mobile review, but I think the desktop review was done within a day.
Steven (Dev) : Because of the time difference with the US, we would submit, go to bed, wake up, and get rejected. 🙂
Q. What were the reasons for the rejections?
Steven (Dev): The first rejection we got was that we shouldn't force the user to install the driver.
Joey (Dev): We were given the guidance not to force driver installation with the phrase 'Do not expose driver installation on the main page view.' Different team members interpreted this differently... We kept testing while submitting reviews, and fortunately, Howard explained well in the comments to the reviewer, so we were able to expose the driver installation on the main page. He put it into words well. 🙂
Howard (PO): We should never go against their wishes.
Steven (Dev): After that, we caught on to other small details. 'The user manual explanation is lacking,' 'It would have been nice to add marketing information,' 'The export function should be completed within 15 minutes.' Also, there were times when they rejected by saying, 'Why didn't you fix what I told you to fix?'... But Howard explained well to the reviewers, and we moved on. There were several back-and-forth communication processes with the reviewers.
Q. How did you feel when your app passed the review?
Steven (Dev): We were in the middle of a meeting thinking, "What if we get rejected again?" and then it just happened.
Howard (PO): I screamed because I was so happy that it passed.
Steven (Dev): I was like, 'Let's finish the meeting quickly.'
Howard (PO): It seemed intentional. So that we would feel happy later. 🙂 It's always nice when they say no at the beginning and then they do it later.
Q. Did the feedback you received during the app registration process actually help you?
Howard (PO): I think it's been a good process, because from Apple's point of view, they're filtering out weird apps in the store because they can destroy the ecosystem. From our perspective, it wasn't bad because we were able to include file handling features and do QA thanks to it.
🎙️ We also interviewed PO Wan to talk about the SDK!
Wan(PO): Hello, I'm Wan. Since this year, I've been in charge of the Product Owner role for the SDK product line. Just Voice SDK was released earlier this year and is being pushed as a flagship product by the SDK squad.
Every SDK product says
it’s easy to integrate,
but after working with customers,
we found that this one is really easy.
Q. Can you give us a brief introduction to the Just Voice Lite SDK?
Wan (PO): It's AI-based, but it can be run on-device, not on a server, like on phones or laptops. And it doesn't take long and can be processed in real-time. Our research head always emphasizes, 'Faster than the blink of an eye.' It's numerically 3/100 of a second, but if you actually hear it, you won't feel the speed at all. So, it's a solution that suppresses noise and only makes voices crisp in any environment with various noises.
Q. What are some scenarios where the Just Voice Lite SDK can help?
Wan (PO): Calls and video conferencing are the most basic scenarios that you can think of, and there are also service cases that are well used by companies that provide radio solutions for noisy industrial sites. Also, when agents are answering calls in call centers, customers often call in noisy environments, right? If you use Just Voice in such scenarios, you can hear your voice clearly.
Q. What are the biggest advantages of the Just Voice Lite SDK?
Wan (PO): Actually, many SDK products claim that integration is very easy, but when we actually worked with customers this year, we found that this one is really easy. We have prepared a well-prepared guide document, so I think you can try it in about 30 minutes. We have uploaded a trial version on our website, so you can apply it directly to your environment, app, or device.
Just Voice Lite SDK can be installed on all laptops and phones. It can be applied to applications running on laptops or phones. We have also prepared a version that can run on low-spec devices, such as wireless earphones, much lower performance than smartphones, so now we can say 'it can run on most devices.' Also, we have many audio experts at GaudioLab, so we quickly consult with experts to provide the parts you need according to the situation. 🙂
Just Voice Lite on the App Store!
Q. Finally, how did you feel about developing Gaudio Lab's first B2C app?
Howard (PO): I think it was a good attempt. We actually did a lot of demos with the app on B2B alone. Saying, 'Try Denoise like this.' So, I think there is meaning in that alone, and more B2C customers will emerge. Please promote it a lot. 🙂
Joy (Dev): It was a good attempt, but I don't think Just Voice Lite is the kind of app that people install and say, 'This looks fun.' What I want to create is a product that anyone can use regardless of age or gender. If there are such ideas, I want to create an interesting product for the next project.
Jack (Dev): Howard has been thinking about putting various sound effects into Just Voice. I think that's one of the points that will make it interesting as Joy mentioned. I don't know when it will happen, but I hope that day comes soon.
Steven (Dev): Since we broke through with the first B2C app at GaudioLab, we gained know-how once. I think there will be fewer trial and error next time.
🎙️ In conclusion…
Through the interview, we were able to glimpse the difficulties encountered and the process of overcoming them while developing the first B2C app. It was a valuable opportunity for me to indirectly experience the entire process of app development. Sincere thanks to the app team for participating in the interview. 🙂
Taking this experience of developing the first B2C app as a stepping stone, Gaudio Lab plans to launch various B2C services gradually. Please show interest in Just Voice Lite and the new services to be launched in the future!


Our audio technologies support various devices and platforms.
