GAUDIO STUDIO Sound Separation Tips - A Sound Engineer's Guide 🐝
Hello, this is Bright, a sound engineer from Gaudio Lab!
These days, many fields are utilizing AI to increase productivity, and I'm sure you've come across AI tools at one point or another. But have you ever wondered how a sound engineer at an audio AI company utilizes AI?
I remember back when I was young, I had to struggle through Google to practice MR production and mixing. I recall the difficulty of separating MRs myself or downloading multi-tracks shared as learning materials. The processes were cumbersome, and even the works completed with such effort, the quality were not so good. 😭
But now, with the era of AI, all that hardship has become a thing of the past! Especially with the commercialization of AI technologies for separating audio sources, many tasks in the audio industry have become much simpler. As a sound engineer, I think it's a great era where we can fully focus on creativity.
Today, I'd like to introduce various tips for GAUDIO STUDIO, one of the tools I use the most. It boasts top-notch performance among various AI audio separation services, and by following along slowly, you too can become a top-notch sound engineer like me😎
🍯 Tip 1 - Create an MR
Step 1 - Separating the vocals
How do I remove vocals from the music in GAUDIO STUDIO?
This is one of the most common questions I get asked, and I believe many people use GAUDIO STUDIO primarily for MR production for events like karaoke, celebrations, and more.
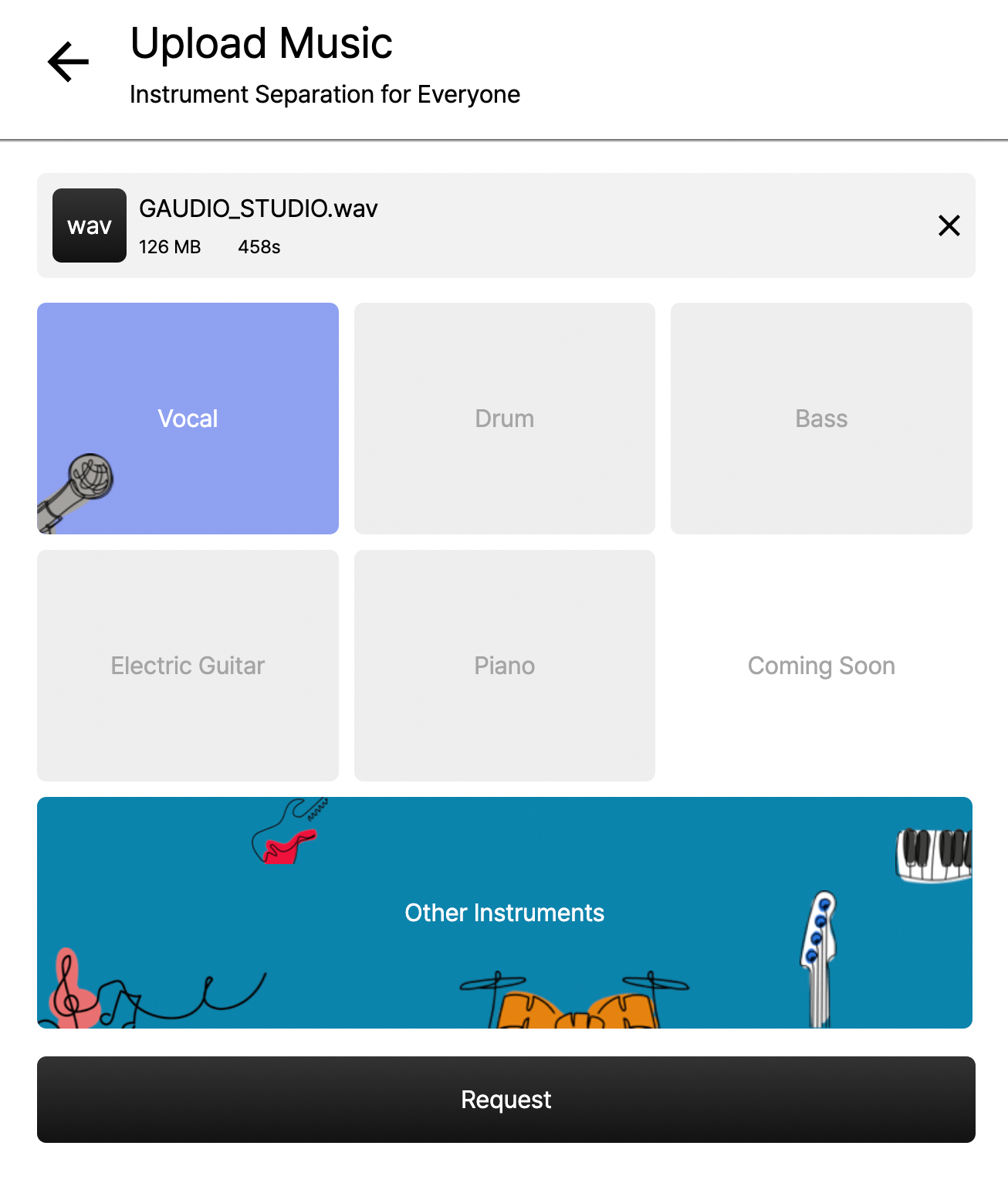
Only 'Vocals' and 'Other Instruments' selected
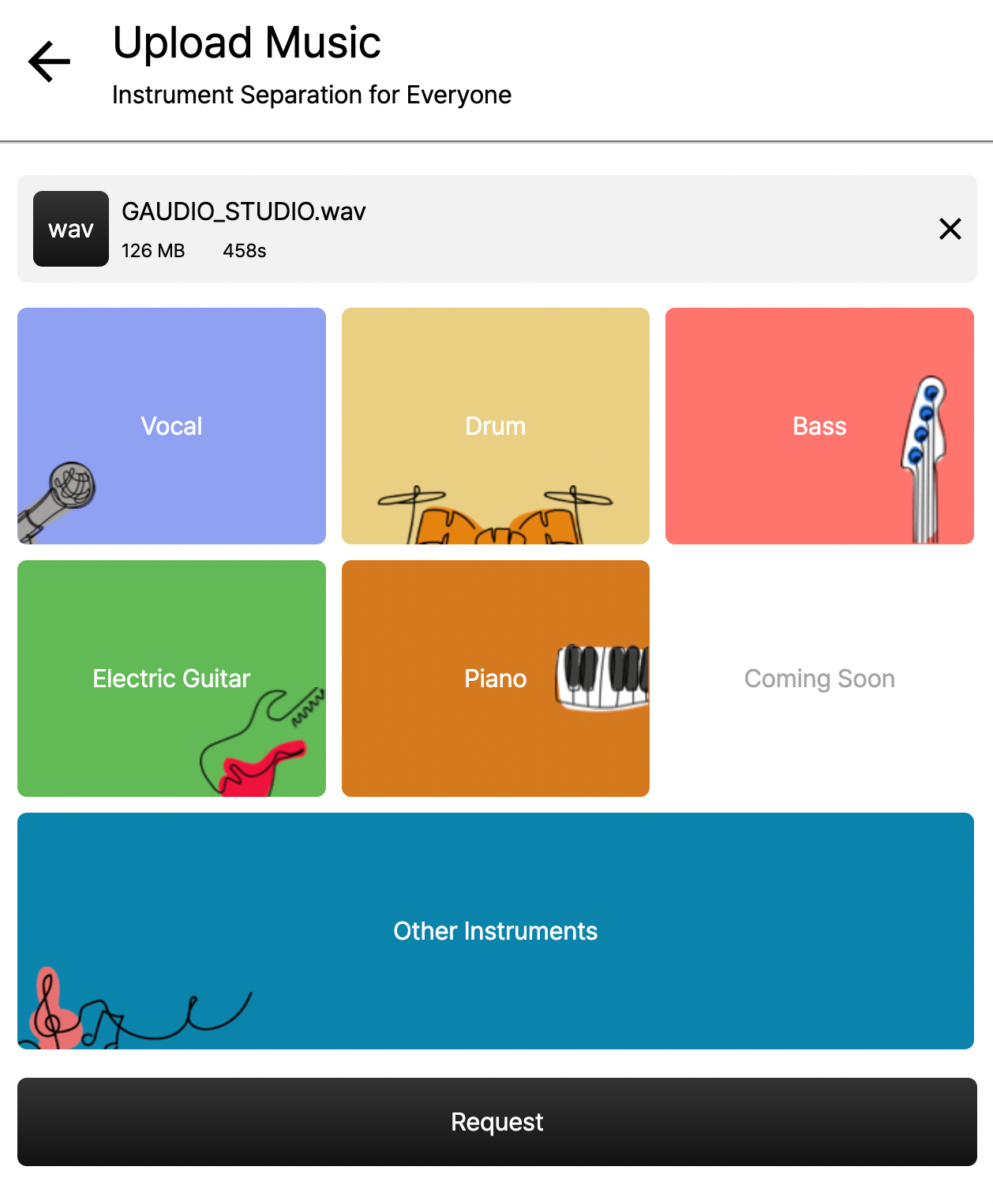 All instruments selected
All instruments selected
In GAUDIO STUDIO, you can separate the sound source by selecting the instruments you want (vocals, drums, bass, electric guitar, piano, and other instruments). So if you select vocals only and separate them, you can create an MR, right?
The AI will take care of the rest, making it easy to create MRs with just a few simple clicks!
Step 2 - Key up / down
How do I customize the key of my MR?
If you don't already have a music editing program, I recommend Audacity - it's free, has tons of hidden features, and I used it a lot during my student days.
Now that you're all set up, let's try it step by step!
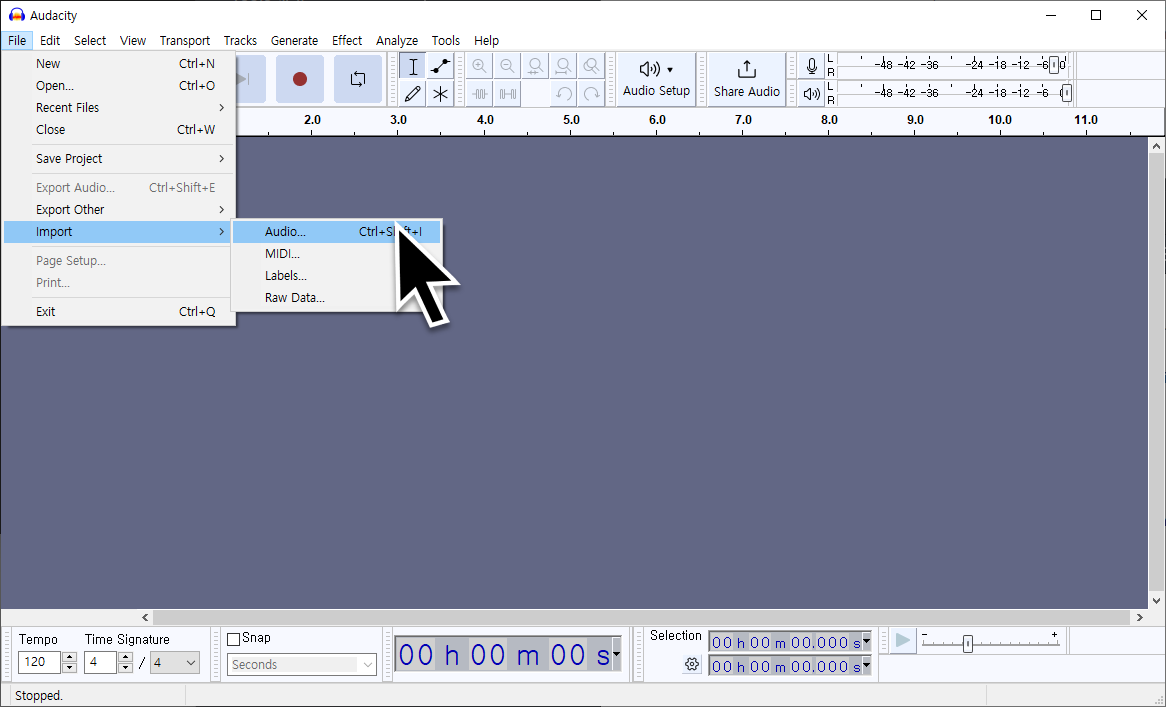
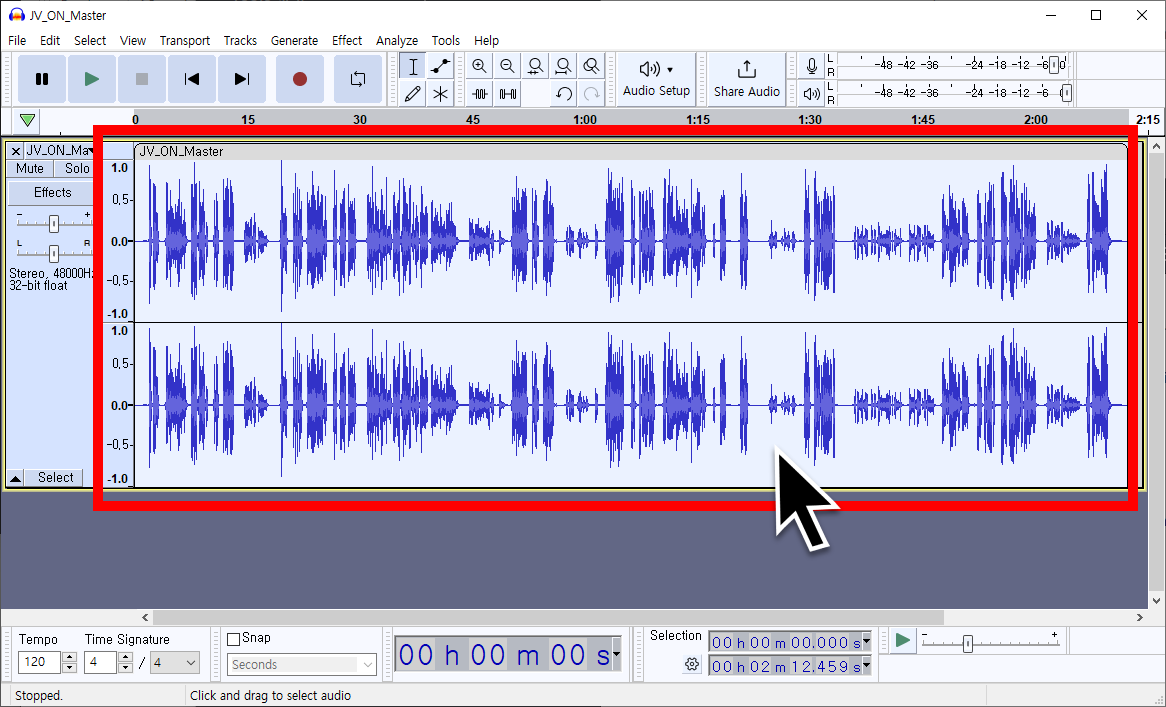
First, click [File] → [Import] → [Audio] at the top to import the sound source, then double-click on the loaded file to select it entirely.
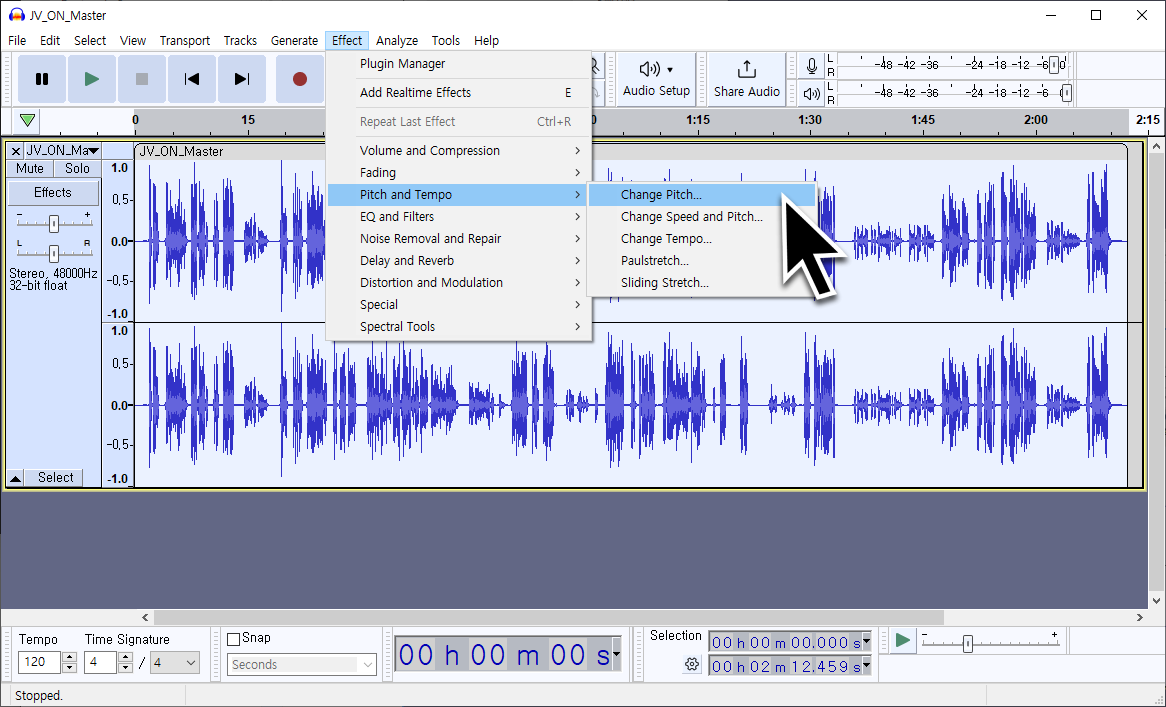
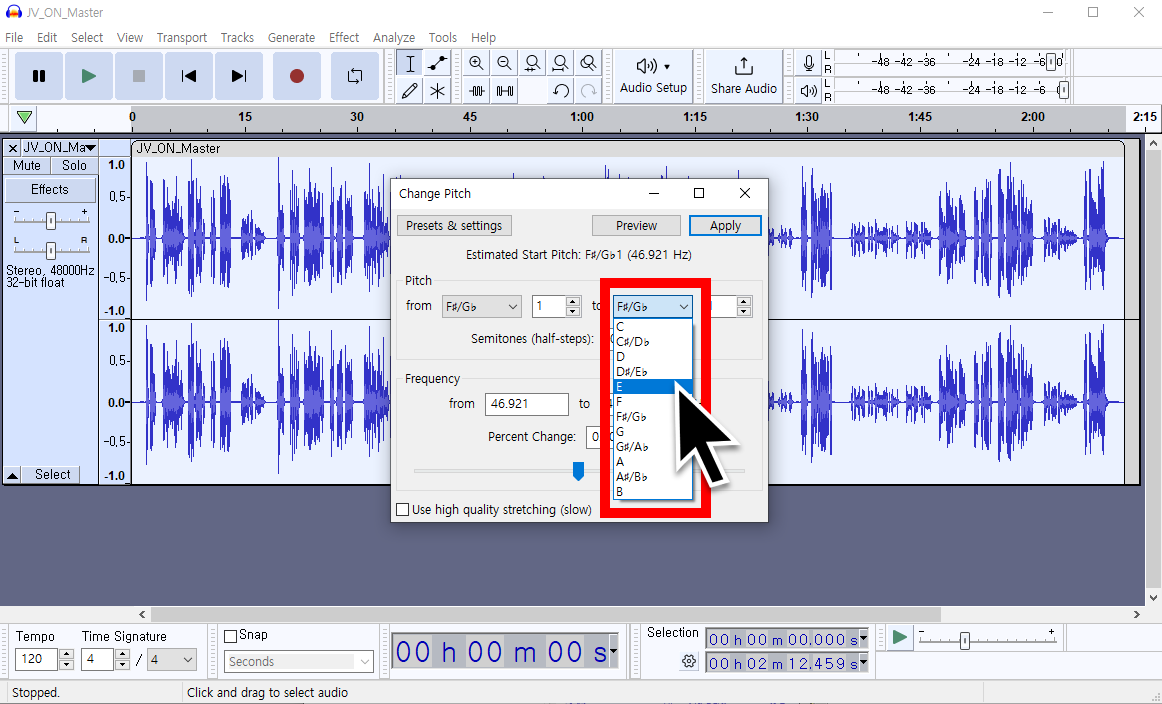
Then, go to [Effect] → [Pitch & Tempo] → [Change Pitch] to adjust the key and that's it!
You can also fine-tune it, so play around with it a few times to get it to the pitch you want.
For those who followed along well so far, do you feel something strange? Or do you want to create a high-quality MR different from others?
There's one thing we often overlook. Drums don't have pitches!
Because of this, if you change the key with a drum track included, the pitch of the drumbeat also changes, affecting the overall quality.
😎 Now, here's a trick: try adjusting the key of the rest of the instruments, this time without the drum track, and then put them back together with the drums. That weird dissonance should be gone!
Step 3 - Put it to use
So what more can I do with this?
After separating the MR and adjusting the keys, you can create content like this.
Do you get the idea? You can create duets with singers who have different vocal keys!
If you further process the separated voices with the Voice Conversion AI learning model, you can also create AI cover content, which is trending these days. Of course, the better the quality of the separated voices, the better the trained results, which is why I've heard that many people use GAUDIO STUDIO a lot. 👀
Aren't you curious about your favorite singer singing songs by other artists?
😎 There are endless possibilities for using GAUDIO STUDIO like this.
🍯 Tip 2 - Adjusting a specific track in an already recorded song
This time, let me show you an example of how you can use GAUDIO STUDIO in situations you might encounter in your daily life.
Situation 1 - You've just finished a really great ensemble, but the drums are just too loud!
In such cases, if you separate only the drum track and adjust the volume, you'll be able to bring out the other instruments. Similarly, reducing excessively thumping beats in concert footage can highlight the artist's voice more.
Even recordings that seemed impossible to separate or footage that seemed impossible to adjust specific sounds can now be excellently mixed and uploaded!
Situation 2. I filmed a vlog in a cafe and it was recorded with copyrighted music!
If you've ever filmed a outdoor vlog for YouTube and the music from a store is recorded along, it could be detected as a copyrighted element, which could limit your monetization. Perhaps until now, you've probably just turned down the volume or raised your voice, and if that didn't work, you might have ended up deleting all the sounds and recording narration separately.
😎 Now, you don't need to do that anymore. Just separate your voice and cleanly remove unwanted music.
With just GAUDIO STUDIO, you no longer have to suffer from unexpected copyright issues!
How did you find the endless applications of AI music separation that I introduced?
I'm often amazed at how tasks that were difficult or required tremendous effort in the past are now so easily accomplished.
Why not use the magic of GAUDIO STUDIO to create and enjoy your own unique content?
GAUDIO STUDIO will continue to evolve until, in the not-too-distant future, all track stems will be neatly separated when you just insert a stereo file.
We look forward to your continued interest and enjoyment!

Our audio technologies support various devices and platforms.
