ICML 2024 탐방기: AI 및 오디오 연구의 최신 동향
들어가며
안녕하세요, 다시 돌아온 카야입니다!
저는 가우디오랩에서 오디오 AI를 연구하고 있다보니 학회에 참석할 일이 종종 있는데요. 얼마 전에도 ICASSP 2024 & Gaudio Night 현장 스케치를 전달 드렸었죠.
이번에는 오스트리아 비엔나에서 열린 ICML 학회에 참석하기 위해 출장을 다녀온 이야기를 풀어보려 합니다.
인공지능(AI) 연구의 중심인 ICML(International Conference on Machine Learning) 2024은 가우디오랩이 매년 참석하는 학회이기도 해요. 이 학회는 매년 전 세계의 연구자와 기업들이 모여 최신 연구 성과를 공유하는 자리로, 저 같은 연구자에게는 늘 가슴 설레는 순간이죠. ICLR, NeurIPS와 함께 세계 3대 인공지능 학회 중 하나이기도 합니다.
현장 분위기를 중점으로 전달했던 저번 포스트와는 달리 이번에는 새로운 아이디어와 영감으로 가득 찬 ICML 2024에서 느끼고 배운 점들을 생생하게 전해드리려 합니다!

2024 ICML 톺아보기
Spotlighted 논문
먼저 이번 학회에서 눈여겨 보고 온 연구들 중 몇가지를 짧게 소개드릴까 하는데요. 첫 번째로 눈길을 끈 것은 "Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution"입니다. 이 연구는 이산적 데이터를 다루는 새로운 접근 방식을 제안했으며, SEDD라는 방법론을 통해 자연어 처리 분야에서 기존의 SOTA 모델(GPT-2 등)보다 뛰어난 성능을 발휘했습니다. 특히, 이 연구는 디퓨전 모델의 활용성을 크게 확장시켜, AI 연구에서 큰 반향을 일으켰습니다.
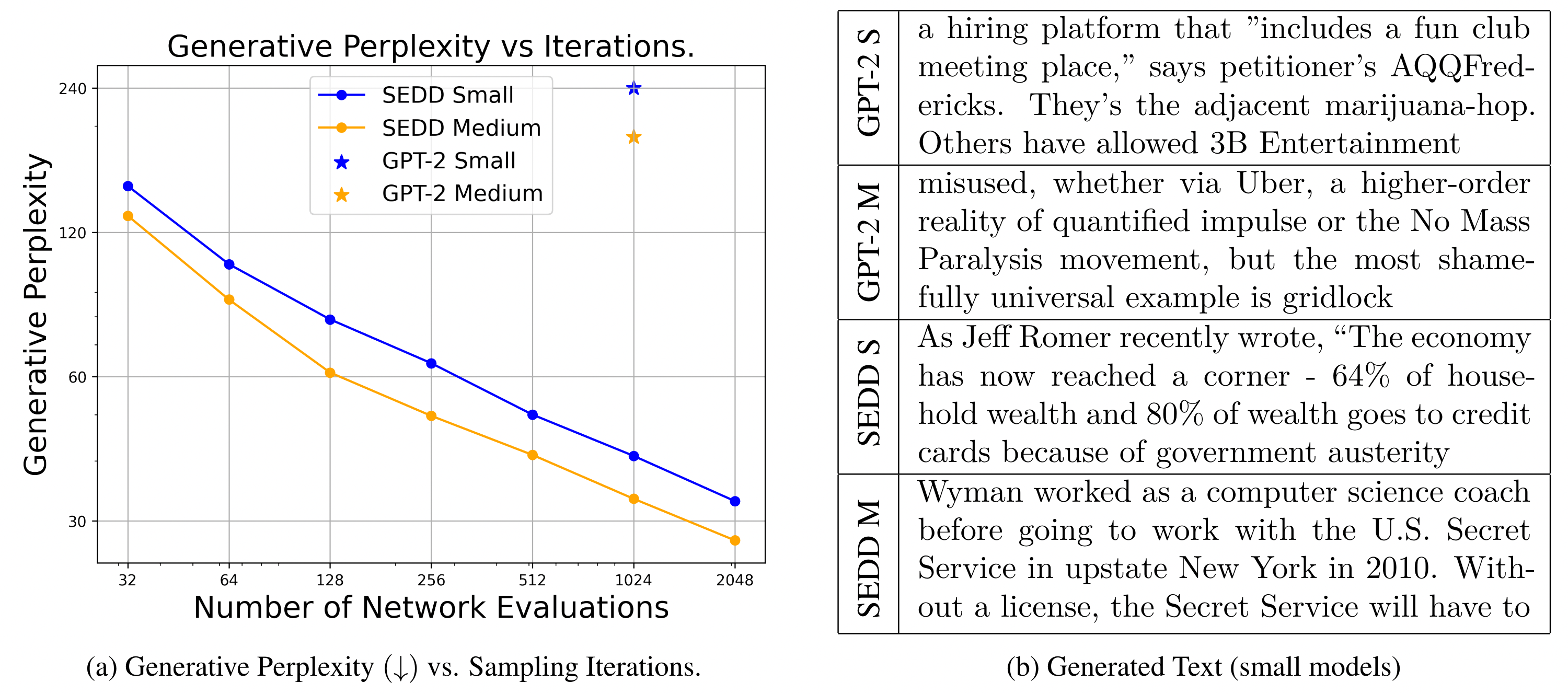
Lou, Aaron, Chenlin Meng, and Stefano Ermon. "Discrete Diffusion Language Modeling by Estimating the Ratios of the Data Distribution."
다음으로 흥미로웠던 연구는 "Debating with More Persuasive LLMs Leads to More Truthful Answers"라는 제목의 논문입니다. 상상 속에서나 가능할 것 같았던 AI 모델 간의 토론(debating)을 통해 모델의 정확도를 높일 수 있다는 놀라운 발견을 실험적으로 증명한 연구였죠. ChatGPT와 같은 언어 모델이 잘못된 정보를 제공하는 문제를 해결하는 데 중요한 기여를 할 수 있을 것으로 기대됩니다.
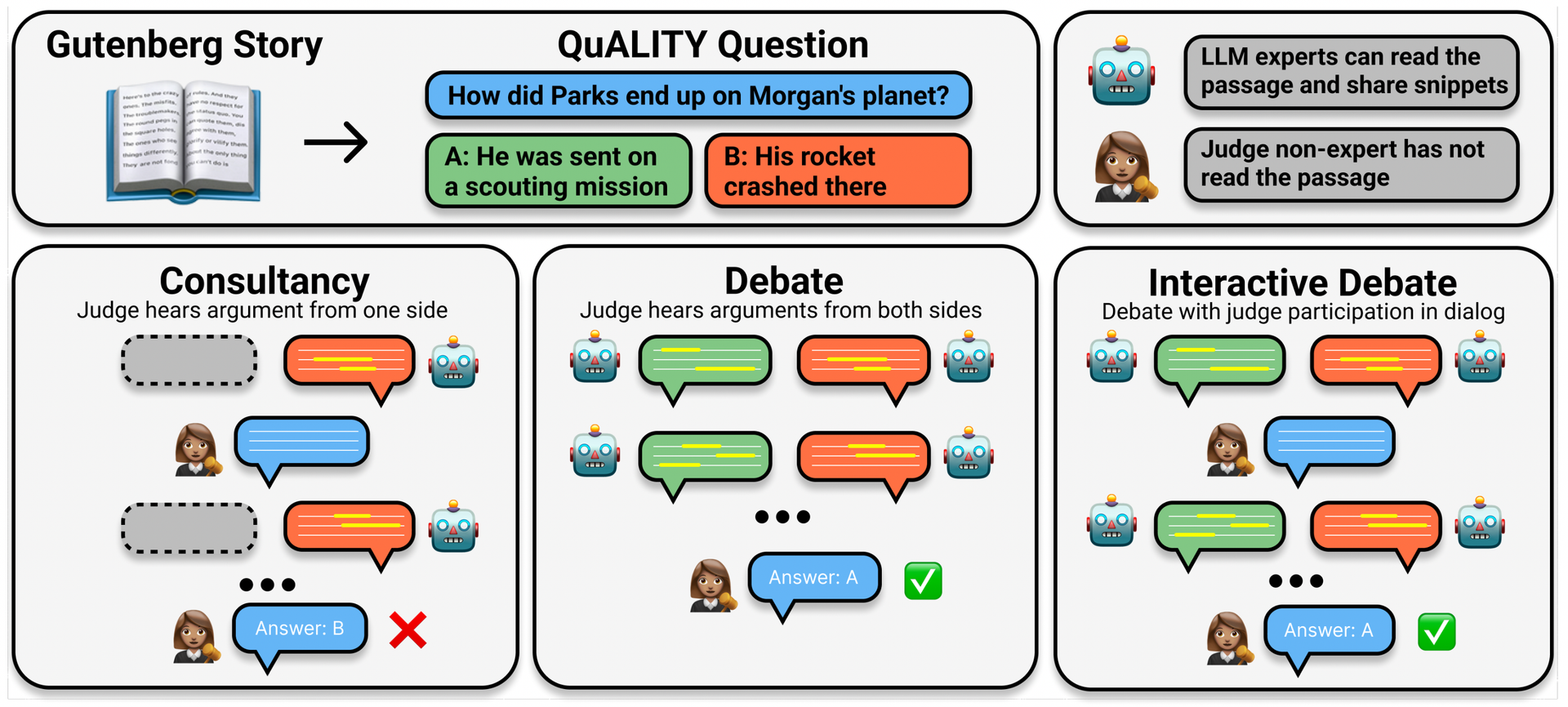
Khan, Akbir, et al. "Debating with More Persuasive LLMs Leads to More Truthful Answers."
“Position” 논문의 등장
올해 ICML에서 새롭게 등장한 논문 유형이 있었는데요, 바로 “Position” 이라는 멋있는✨ 접두사가 붙은 논문들입니다. 이 논문들은 새로운 모델이나 아이디어를 제안하기보다는 현재 학계의 통념에 대한 깊은 고찰과 의문을 제기하는 데 중점을 둡니다.
제가 특히 흥미를 느꼈던 주제는 "Position: Measure Dataset Diversity, Don't Just Claim It"이라는 제목의 논문이었습니다. 이 연구는 데이터셋의 다양성을 측정할 때 단순히 '다양하다'고 주장하는 것만으로는 부족하다고 지적하며, 무려 135개의 이미지 및 텍스트 데이터셋을 분석한 결과를 통해 데이터셋의 다양성에 대한 새로운 시각을 제공했습니다. AI 연구자로서 데이터셋의 공정성과 포괄성에 대해 더욱 깊이 고려해야 할 점을 일깨워 준 중요한 논문이었습니다.
Audio 연구의 트렌드
이번 ICML에서는 오디오 AI 연구에서도 많은 흥미로운 논문들이 발표되었습니다.
오디오 AI 연구의 최근 트렌드는 더욱 정교한 생성 모델에 집중하고 있으며, 이 트렌드는 음악 생성부터 범용 오디오(음성 및 효과음 등) 합성까지 다양한 영역에서 뚜렷하게 나타나고 있습니다.
가장 인상 깊었던 연구 중 하나는 "DITTO: Diffusion Inference-Time T-Optimization for Music Generation"이라는 논문이었는데요. 이 논문은 음악 생성에서 생성될 음악의 강도(intensity), 멜로디(melody) 및 구조(musical structure)를 정밀하게 제어할 수 있는 기술을 제안했습니다. 음악 AI가 앞으로 얼마나 더 정교해질지 정말 기대되지 않나요?
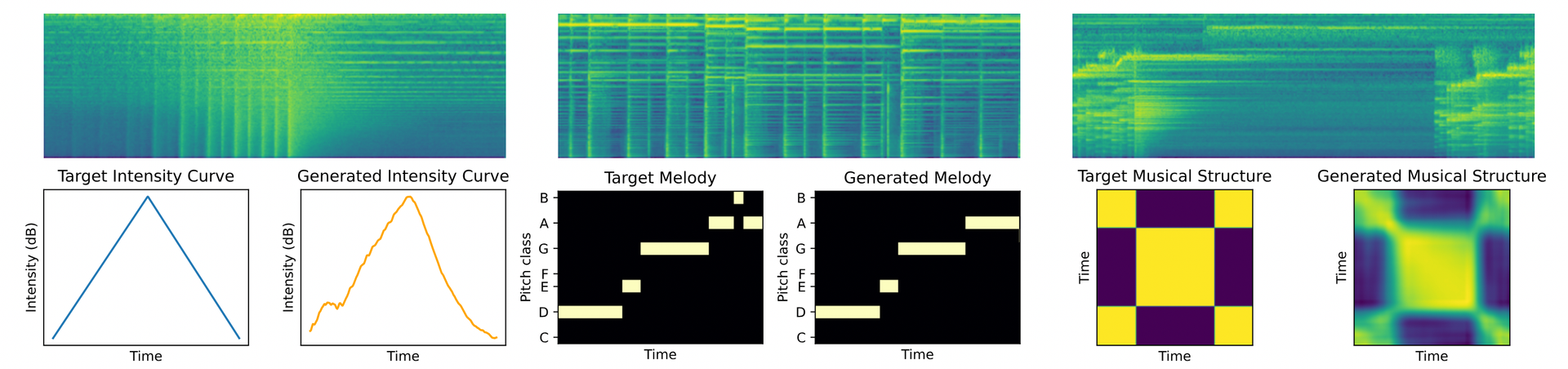
Novack, Zachary, et al. "Ditto: Diffusion inference-time t-optimization for music generation."
뿐만 아니라, 비디오로부터 오디오를 생성하는 Video-to-Audio Generation도 매우 핫한 주제로 떠오르고 있습니다. OpenAI에서 공개한 비디오 생성 AI “Sora”, 다들 보신 적 있으시죠? 이렇게 높은 퀄리티의 비디오 생성이 가능해지면서, 비디오에 어울리는 오디오를 생성하는 작업이 중요한 연구 주제로 떠오르고 있는 것인데요. Google에서는 비디오와 오디오를 동시에 생성하는 모델을 "VideoPoet"이라는 이름으로 제안했고, Adobe에서는 비디오의 액션에 싱크를 맞춘 효과음을 생성하는 "Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity" 연구를 발표했습니다.
이런 연구들을 보면 가우디오랩의 효과음 생성 모델 FALL-E가 생각나지 않을 수 없는데요. Microsoft의 CEO 사티야 나델라가 CES때 직접 관심을 보인 기술이기도 하죠. 저희 가우디오랩에서도 역시 이미 몇달 전, FALL-E로 Sora 비디오에 맞추어 효과음을 생성한 결과를 공개한 적이 있었어요! 위 연구들을 보며 가우디오랩이 이런 학계의 트렌드를 발 빠르게 캐치하고 있구나😎 하는 뿌듯한 마음과 함께 팀의 연구 방향에 대한 확신이 더해질 수 있었습니다.
마치며
이렇게 ICML 2024에서 본 AI 연구의 다양한 트렌드와 흥미로운 연구들을 짧게 소개해드렸는데요.
실제로는 궁금한 연구가 너무 많아 큰 학회장을 열심히 뛰어다니며 바쁜 일정을 소화했더랍니다. 🏃♀️

종이 상자 안에 거대 언어 모델(LLM)에 대한 여러가지 질문 쪽지를 준비해놓고, 쪽지를 뽑은 연구자들끼리 알아서 불 튀기게 토론하도록 한 포스터 발표 방식이 신선하고 재밌었어요. 일종의 자동 사냥 같은…
이렇게 이번 ICML 2024에서 AI 연구의 다양한 트렌드와 흥미로운 연구들을 직접 보고 들으면서 많은 영감을 받고 한국으로 돌아왔습니다. 이번 학회에서 얻은 지식과 영감을 바탕으로 더 똑똑한 AI 모델을 개발하기 위해 다시 열심히 달려봐야겠죠?ㅎㅎ
다음 학회에서는 가우디오랩 리서치 팀의 연구를 Spotlighted 논문으로 소개하게 되는 날이 오길 바라며💪 ICML 2024 후기는 여기서 마무리 하겠습니다. 😁!


다양한 디바이스와 플랫폼에 적용 가능한 오디오 기술을 만나 보세요
