WebRTC에 Audio AI SDK 통합하기 (2) : 효과적인 통합 개발을 위한 테스트 환경 구축 방법
WebRTC에 Audio AI SDK 통합하기 (2) : 효과적인 통합 개발을 위한 테스트 환경 구축 방법
(Writer: Jack Noh)
지난 포스트를 통해 WebRTC와 그 오디오 파이프라인에 대해 간단히 설명드렸던 것처럼, WebRTC는 매우 거대한 멀티미디어(오디오, 비디오, 데이터 전송 등) 기술이며, 오디오 부분만 보더라도 여러 모듈들(APM, ACM, ADM, …)이 존재합니다. 그만큼 활용 범위가 높은 기술이기도 한데요, 이번 포스팅에서는 WebRTC에 오디오AI SDK를 통합하는 과정 중 매우 중요한, ‘견고한 테스트 환경’을 구축하는 방법에 대해 이야기 해보려고 합니다.
WebRTC Audio Processing Module
WebRTC의 오디오 모듈들 중에 노이즈 제거 필터를 통합하기 가장 적합한 모듈은 무엇일까요? 사실 앞선 포스트를 읽어보셔서 눈치채셨겠지만, 이런 다른 SDK를 통합하기에 적합한(사실상 통합을 위해 만들어놓은) 모듈은 바로 APM(Audio Processing Module)입니다. 애초에 APM 자체가 통화 품질을 높이기 위한 신호 처리 기반의 오디오 신호 필터들을 모아놓은 모듈이기 때문입니다.
Audio Processing Module은 주로 단말(Client-side)에서 오디오에 효과를 주는 핵심 모듈입니다. 이 모듈은 오디오 신호를 통화(call)에 적합한 좋은 품질로 향상 효과를 주는 목적으로 필터들을 모듈화해놓은 것입니다. APM 모듈의 필터들은 Sub-module로 불리며 다양한 역할을 수행합니다.
WebRTC의 대표적인 Submodule들을 간략히 소개하자면 아래와 같습니다.
-
High Pass Filter(HPF): 저주파수 신호를 제거하여 목소리 같은 고주파 신호만을 추출하는 필터
-
Automatic Gain Controller(AGC): 오디오 신호의 크기를 자동으로 조절하여 일정한 수준으로 유지하는 필터
-
Acoustic Echo Cancellation(AEC): 스피커에서 나오는 신호(Far-end)가 다시 마이크로 들어가는 에코를 제거해주는 필터
-
Noise Suppression(NS): 주변 환경음(노이즈)를 제거해주는 신호처리 기반의 필터
이러한 Submodule들은 Near-end Stream(마이크 입력 신호를 상대방에게 전송)과 Far-end Stream(상대방으로 부터 수신 받은 오디오 데이터를 스피커로 출력)에서 각각 알맞게 활용되는데요. 화상회의 하는 시나리오를 예를 들어서 설명드려볼게요.
먼저 마이크에 입력된 오디오 신호는 저주파수 잡음을 제거하기 위해 High Pass Filter(HPF)를 거치게 됩니다. 다음에 갑자기 큰 소리로 인해 청감적인 불편함을 없애기 위해서 자동으로 신호 크기를 제어하는 Automatic Gain Controller(AGC)를 거치게 되죠. 그 이후에 에코(스피커에서 나오는 신호가 다시 마이크로 들어가는 것)를 방지하고자 Acoustic Echo Cancellation(AEC)를 통하게 됩니다. 그 이후에 주변 환경 노이즈를 제거하는 Noise Suppressor(NS)를 거치는 것이죠.
글 보다는 그림으로 표현하는게 훨씬 간단합니다. 아래 그림에서 ProcessStream()이란 마이크에서 입력받은(Capture) 신호 Stream의 프로세싱을 나타냅니다. 정방향이란 표현을 쓰기도 합니다. 동시에 ProcessReverseStream()은 원격의 상대(Peer)로 부터 온 오디오 데이터를 SPK로 출력(Render)하기 위한 역박향 Stream을 프로세싱하기 위해 존재합니다. 각 프로세싱은 Near-end Stream과 Far-end Stream의 APM에서의 효과 처리 과정이라고 이해해 주시면 됩니다.
위에서 설명한 흐름에 대해 아래 그림으로 한번 더 확인해보시죠.
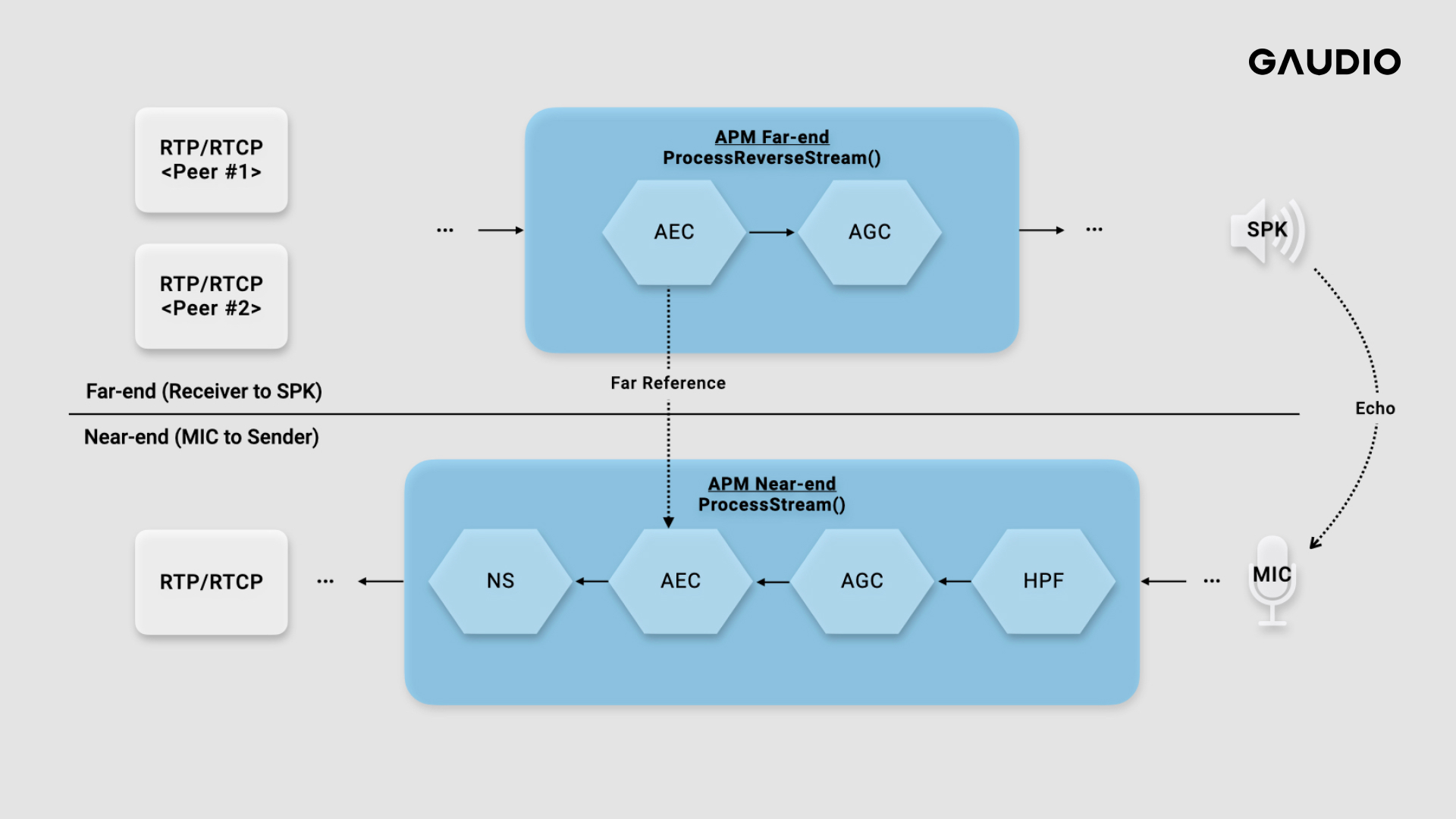
(WebRTC Branch: branch-heads/5736)
참고로 두 Stream의 프로세싱은 독립적이지 않습니다. 왜냐하면 상대방이 말하는 목소리가 다시 마이크로 들어가는 에코를 지워주기 위해서는 ProcessReverseStream()에서 신호를 분석 한 후에 ProcessStream()가 넘겨 받아 이 에코를 지워줘야 하기 때문입니다. (위에서 설명한 AEC의 역할!)
자, WebRTC의 APM은 이러한 구조로 이루어져있다는 것을 파악하였고, 여기에 저는 가우디오랩의 뛰어난 음원분리 기술인 GSEP-LD를 통합하고자 했는데요. 직관적으로 보면 NS 자리에 GSEP-LD를 대체하는 것이 좋을 것 같습니다만, 과연 그럴까요?
신호 처리의 관점에서는 그렇게 보일 수 있지만, 우리가 통합하고자하는 SDK는 인공지능 기반이기에 아직 확단할 수는 없습니다. AEC 전에 통합하는 것이 효과를 높일 수도 있고요, 혹은 반대로 아예 끝단에 통합을 하는것이 효과가 좋을 수도 있습니다.
‘최적의 통합 위치는 기존 노이즈 제거 필터의 위치와 같을까요?’의 질문에 이어 숱한 의문들이 생겨납니다.
‘다른 Submodule과의 Side-Effect는 없을까요?’
‘NS와 GSEP-LD를 동시에 사용해보는건 어떨까요?’
‘저주파 노이즈를 제거하기 위한 HPF 필터까지 굳이 사용해야 할까요?’
‘AEC 동작 여부에 따라 GSEP-LD 성능은 어떻게 달라질까요?’
WebRTC의 APM을 분석해보니 테스트로 챙겨야할 것들이 생각보다 많았습니다. 이제 이러한 경우들을 견고하게 테스트하기 위한 방법을 알아보도록 합시다.
참고로 WebRTC에 다른 SDK를 Submodule로 통합하는 방법은 어렵지 않습니다. 본 글은 WebRTC Audio 파이프라인의 테스트 환경 구축에 대한 이야기에 한정하기에 자세히 다루지는 않습니다만, 짧게 설명드리자면 이렇습니다.
WebRTC APM은 C++ 언어로 작성되어 있는데, 먼저 APM의 다른 Submodules과 동일하게 인스터스 및 상태를 관리하기 위해 Wrapper Class를 작성합니다. 그 이후에 실제 APM Class에 통합하고자하는 Wrapper Class 다른 Submodules을 참고해서 같은 방식으로 관리해주면 됩니다.
효과적인 통합을 위한 APM CLI 활용하기
이제 APM 모듈에 대한 이해를 바탕으로 견고한 테스트 환경을 구축하여 GSEP-LD의 결과를 얻어보도록 하겠습니다. 이를 위해서는 APM만 독립적으로 실행이 가능한 CLI(Command Line Interface)를 만들어 파일 출력 결과를 얻어보는게 효과적입니다. (실제로 들어보기도 해야하기 때문 입니다!)
저희가 파악한 효과적인 통합을 위해 APM CLI를 사용하는 방법은 2가지 입니다.
첫 번째 방법은 1)WebRTC 오픈 소스에서 바로 사용이 가능한 방법이며,
두 번째 방법은 2)WebRTC APM만 단독으로 있는 오픈소스 프로젝트를 활용하는 방법 입니다.
1) WebRTC 오픈 소스에서 바로 사용이 가능한 방법
WebRTC 오픈 소스는 링크에서 바로 확인이 가능합니다. WebRTC 프로젝트에는 플랫폼 별 빌드 방법에 대한 가이드가 자세히 나와있습니다. 소스 코드를 받고 가이드를 따라 필요한 소프트웨어들을 설치하고 빌드가 성공했다면, APM CLI를 사용할 수 있는 준비 끝입니다!
빌드 경로를 확인하면 산출물로 APM의 파일 모드 테스트 툴인 audioproc_f을 확인할 수 있습니다. audioproc_f를 활용한다면, APM에 WAV 파일을 입력하여 APM의 오디오 필터 효과가 적용된 결과를 얻을 수 있습니다. Default 옵션으로 APM 수행 결과 확인하기 위해서는 아래와 같이하면 됩니다.
$ ./audioproc_f -i INPUT.wav --all_default -o OUTPUT.wav
세부 옵션을 사용하면, 구체적인 테스트 환경을 시험하는 것도 가능합니다. 이번에는 Near-, Far-End 간의 Stream Delay를 30ms로 설정하고, Noise Suppressor를 켜보도록 하겠습니다. 여기서 Stream Delay란 하드웨어 및 시스템에 의한 지연을 의미합니다. 참고로 AEC의 성능을 높이기 위해서는 Near-, Far-End 간의 Stream Delay를 정확히 기술해야 하는 것이 중요하기 때문에 때문에 테스트 시에 유의해야할 파라미터 입니다.
./audioproc_f -i INPUT.wav --use_stream_delay 1 --stream_delay 30 --ns 1 -o OUTPUT.wav
2) WebRTC APM만 단독으로 있는 오픈소스 프로젝트를 활용하는 방법
첫 번째 방법으로도 충분한 테스트를 해볼 수 있을 겁니다. audioproc_f 소스 코드를 수정한다면 견고한 테스트 환경 구축할 수도 있겠죠. 하지만 WebRTC 프로젝트에는 오디오 이외의 불필요한 다른 멀티 미디어 소스 코드들(비디오, 데이터 네트워크 소스 코드, 오디오만 하더라도 ADM, ACM 등 다른 모듈 등..)도 함께 있어 불편한 단점이 있습니다. 그래서 필요한 부분(APM)만 눈에 보이고 좀 더 경량화된 테스트 환경을 구축할 수는 없을까 고민을 하게 되었는데요. 우리는 WebRTC의 APM 모듈만 떼어서 테스트를 구성하는 건 어떨까 고민하던 중 괜찮은 오픈 소스 프로젝트를 발견했습니다. 이 것이 바로 두 번째 방법입니다.
두 번째 방법에서 사용한 오픈 소스의 링크 입니다. 해당 프로젝트는 WebRTC의 APM만 분리해내어 Meson 빌드 시스템을 활용해서 빌드할 수 있는 프로젝트 입니다.
여기서 잠깐! Meson은 CMake 같은 다른 빌드 시스템 보다 빠르게 코드를 빌드할 수 있고, 직관적인 문법 덕분에 다루기 쉽다는 장점이 있는 차세대 C++ 빌드 시스템 입니다. 게다가 테스트 케이스를 다루는 방법도 정말 편리하고 테스트 구조를 쉽게 관리 할 수 있습니다. Meson에서 유닛 테스트를 작성하려면, 테스트 코드를 포함하는 테스트 실행 파일을 생성하고, 해당 파일에서 테스트 코드를 작성합니다. 그런 다음 test() 함수를 사용하여 테스트를 정의하고 Meson에 테스트를 실행하도록 지시합니다. 예를 들어, 다음과 같은 코드를 작성할 수 있습니다.
test('test_name', executable('test_executable', 'test_source.cpp'), timeout: 10)
이 코드는 test_name이라는 이름의 테스트를 정의합니다. 그리고 test_source.cpp 파일에서 빌드된 테스트 실행 파일 test_executable를 실행하여 테스트를 수행합니다. timeout 매개 변수는 테스트가 수행되는 시간을 초 단위로 지정합니다. 만약 지정된 시간 이내에 테스트가 완료되지 않으면 실패로 처리됩니다. 참고로 테스트 실행 파일에는 Arguments도 받을 수 있으니 테스트 마다 다른 값을 적용해서 다양한 케이스를 커버할 수 있습니다.
Meson 빌드 시스템의 쉬운 테스트 코드 작성 방법을 알아 보았습니다. 다음으로 GSEP-LD를 통합하기 위한 테스트를 구성해볼 차례 입니다. 아래 그림이 저희가 구성했던 테스트(실제로 테스트 해본 것보다는 간략화되어 있지만) 설계를 잘 보여줍니다.

먼저 테스트를 크게 2가지 그룹으로 나누었습니다. WebRTC에는 2가지 Stream Near-, Far-end Stream 2가지 존재하는 것, 알고 계시죠? 이를 각각 그룹(A)과 그룹(B)로 나누었습니다.
두 그룹의 큰 차이는 에코를 지워주는 AEC의 동작 유무입니다. (Near-end만 켜지는 그룹은 AEC가 off 상태, Near-, Far-end Stream 모두 사용할 때에는 AEC on 상태입니다.)
각 그룹에 입력되는 파일 구성도 차이가 있습니다. 그룹(A)의 경우에는 마이크를 통해 말하는 소리에 노이즈가 더해진 신호만 입력하면 됩니다. 하지만 그룹(B)에는 스피커에서 나오는 신호(=상대방이 말하는 신호)와 이 스피커에서 나오는 신호가 에코로 다시 들어가는 환경을 모사해주어 합니다. 이 역할을 하는 것이 echo_generator입니다. echo_generator로부터 나온 에코와 마이크를 통해 말하는 신호를 더해주면 그룹(B)의 입력 신호가 완성됩니다.
다음으로 GSEP-LD를 제어하기 위해서 통합 자리와 동작 여부를 제어했습니다. 통합 자리는 프로세싱의 맨 앞쪽(Pre-processing), 기존 노이즈 제거 필터의 자리, 그리고 맨 끝쪽(Post-processing)으로 제어하였습니다.
다른 Submodule과 사이드 이펙트도 볼 필요가 있겠죠? NS와의 사이드 이펙트를 살펴보도록 합시다. NS와의 Side-effect 검증을 위해서 끄거나 켜보고 얼마나 노이즈를 제거할지 Parameter 값을 설정하였습니다. 참고로 NS에서 얼마나 노이즈를 제거할지 Parameter 값은 Low ~ VeryHigh까지 설정이 가능한데, 너무 큰 값을 사용하면 음질에 왜곡이 심해지는 것을 확인할 수 있습니다.
끝으로 입력 파일의 소음을 타입별로 나누었습니다. 카페에서의 소음, 자동차 소음, 빗소리 등 다양한 소음의 종류를 테스트로 분류하였습니다. 자, 이 정도로만 해도 테스트의 가지수가 꽤 많습니다. (각 독립적인 가지수가 곱해지기 때문에…) 하지만 Meson 빌드 시스템의 테스트 기능을 활용한다면 for-loop 몇번으로 쉽게 만들 수 있습니다. 아래는 Meson 빌드 파일을pseudo code로 적어보았습니다.

이렇게 작성하면 테스트 코드의 완성입니다. 이제 Meson 명령어를 통해서 작성된 테스트 코드를 실행하면 우리가 구분한 테스트 가지 수 모두를 커버하며 출력 결과를 얻을 수 있습니다.

결론
WebRTC처럼 여러가지 기술들이 포함된 프로젝트에 제 3의 기술을 통합해보는 꽤 신경 써야 할 일이 많습니다. 통합 자리 선정을 위해서 전체적인 흐름을 이해해야 하고, 다양한 환경에서의 통합을 고려해야 합니다. 통합 위치, 사용 환경, 기존의 다른 기술들과의 Side-Effects등 말이죠. 위에서 언급된 내용은 당장 간단한 경우만 고려한 것입니다. 그럼에도, 노이즈 타입(5가지) x AEC On/Off(2가지) x NS 설정(5가지) x GSEP On/Off(2가지) = 100가지의 케이스!
이렇게 100가지의 케이스를 고민해야 합니다. 하지만 실제로는 노이즈 타입도 더 다양하게 테스트해봐야할 필요가 있으며, NS 이외의 Submodules 까지 고려를 하고, 플랫폼 별(Windows, MacOS, …) 까지 고려하면 테스트 가지수가 곱으로 많아지죠. 그리고 테스트를 위해서 GSEP 위치를 더 다양한 위치에 제어해보게 된다면 머리가 복잡해집니다. 😇
이번 글에서는 이러한 복잡한 가지수를 좀 더 쉽게, 그리고 경량화된 CLI 환경으로 테스트 해 본 경험을 소개해보았습니다. WebRTC의 APM만 분리해놓은 오픈 소스 프로젝트, Meson 빌드 시스템의 Test 기능 등을 활용하면 비교적 쉽게 환경을 구축할 수 있다는 것을 경험하였습니다. 앞으로 WebRTC에 여러분들이 붙여보고 싶은 오디오 필터가 있다면, 이 글이 조금이라도 테스트하는데 있어 도움이 되길 바라며 마치도록 하겠습니다. 읽어주셔서 감사합니다.
아참, WebRTC에 가우디오랩 만의 오디오 SDK를 통합하여 서비스를 만들고 싶으신 분! 언제든 환영합니다.
그리고 WebRTC의 오디오 파이프 라인에 대해 알려주셨으며, 그리고 WebRTC APM만 단독으로 있는 오픈소스 프로젝트를 활용하는 아이디어를 주신 쎄오에게도 땡큐!

세계적인 음향 기술을 보유한 가우디오랩에 지원해 보세요.
