WebRTC에 Audio AI SDK 통합하기 (1) : WebRTC의 오디오 파이프라인 들여다보기
WebRTC에 Audio AI SDK 통합하기 (1) : WebRTC의 오디오 파이프라인 들여다보기
(Writer: Jack Noh)
WebRTC, 그게 궁금해요!
MDN 문서에서는 WebRTC(Web Real-Time Communication)를 아래와 같이 설명하고 있습니다.
(참고로 MDN 문서는 웹 개발을 한다면 한번은 보게 되는, 사실상 표준 문서입니다.)
WebRTC(Web Real-Time Communication)는 웹 애플리케이션과 사이트가 중간자 없이 브라우저 간에 오디오나 영상 미디어를 포착하고 마음대로 스트림 할 뿐 아니라, 임의의 데이터도 교환할 수 있도록 하는 기술입니다. WebRTC를 구성하는 일련의 표준들은 플러그인이나 제 3자 소프트웨어 설치 없이 종단 간 데이터 공유와 화상 회의를 가능하게 합니다.
쉽게 말해 ‘인터넷만 연결되어 있다면 브라우저에서 별도의 소프트웨어의 설치 없이 실시간 통신을 가능하게 해주는 기술’이라고 할 수 있습니다. WebRTC를 활용한 대표적인 서비스로는 화상 회의 서비스인 Google Meet과 음성 통신 서비스인 Discord가 있죠. (실제로 Covid-19 확산기에 뜨거운 관심을 받았던 기술이기도 하고요!) WebRTC는 웹 표준이자 오픈 소스 프로젝트로, 링크를 통해 소스 코드를 확인하고 수정할 수도 있기도 합니다.
WebRTC의 Audio 파이프라인에 대해
WebRTC는 멀티 미디어 기술로서, 오디오, 비디오, 데이터 스트림 등 다양한 기술을 포함하고 있습니다. 그 중에서도 저는 이번 글을 통해 WebRTC의 오디오 기술과 관련된 이야기를 해보려 합니다.
WebRTC를 사용하는 화상 회의나 음성 통화 웹 어플리케이션(e.g. Google Meet)을 사용해본 적이 있다면, Audio 파이프라인이 어떻게 구성되는지 궁금해하실 겁니다. Audio 파이프라인은 2가지 Stream(흐름)으로 구분할 수 있습니다. 먼저 1)마이크 장치를 통해 입력된 음성 데이터가 상대방에게 전송되는 Stream, 그리고 동시에 2)상대방의 음성 데이터를 수신하여 스피커를 통해 출력되는 Stream입니다. 각각은 Near-end Stream(마이크 입력 신호를 상대방에게 전송)과 Far-end Stream(상대방으로 부터 수신 받은 오디오 데이터를 스피커로 출력)으로 불립니다. 각 Stream을 좀 더 자세히 살펴보면 아래와 같은 5가지 과정으로 정리할 수 있습니다.
1) Near-end Stream (마이크 입력 신호를 상대방에게 전송)
-
마이크 장치로부터 오디오 신호를 입력 받는다. (ADM, Audio Device Module)
-
입력 오디오 신호에 통화 품질을 높이기 위한 효과를 준다. (APM, Audio Processing Module)
-
함께 전송할 다른 오디오 신호(e.g. 파일 스트림)가 있다면 함께 Mixing 한다. (Audio Mixer)
-
오디오 신호를 Encoding 한다. (ACM, Audio Coding Module)
-
RTP 패킷으로 변환후 UDP Transport로 전송한다. (Sending)
2) Far-end Stream(상대방으로 부터 수신 받은 오디오 데이터를 스피커로 출력)
-
연결된 상대방(N개의 Peer)으로 부터 오디오 데이터 RTP 패킷을 받는다. (Receiving)
-
각 RTP 패킷을 Decoding 한다. (ACM, Audio Coding Module)
-
Decoding된 N개 스트림을 1개 스트림으로 Mixing 한다. (Audio Mixer)
-
출력 오디오 신호에 통화 품질을 높이기 위한 효과를 준다. (APM, Audio Processing Module)
-
스피커 장치로 오디오 신호를 출력 한다. (ADM, Audio Device Module)
각 과정을 담당하는 모듈의 이름은 위 설명에서 우측 (괄호)로 표시해두었는데요. 이처럼 WebRTC에서는 각 과정 별로 모듈화가 잘 되어 있습니다.
각 모듈에 대해 보다 더 자세히 살펴보면 이렇게 설명드릴 수 있는데요.
-
ADM(Audio Device Module): 입/출력 하드웨어 영역과 접해 있으며 오디오 신호를 Capture/Render 할 수 있게 해줍니다. 플랫폼(Windows, MacOS, …) 별로 그에 맞는 API로 구현되어 있습니다.
-
APM(Audio Processing Module): 통화 품질을 높이기 위한 오디오 신호처리 필터들의 모음입니다. 주로 단말(Client)에서 활용 됩니다.
-
Audio Mixer: 여러 개의 오디오 스트림을 합쳐줍니다.
-
ACM(Audio Coding Module): 전송/수신을 위해 오디오 인코딩/디코딩 합니다.
이를 그림으로 표현하면 아래와 같습니다.
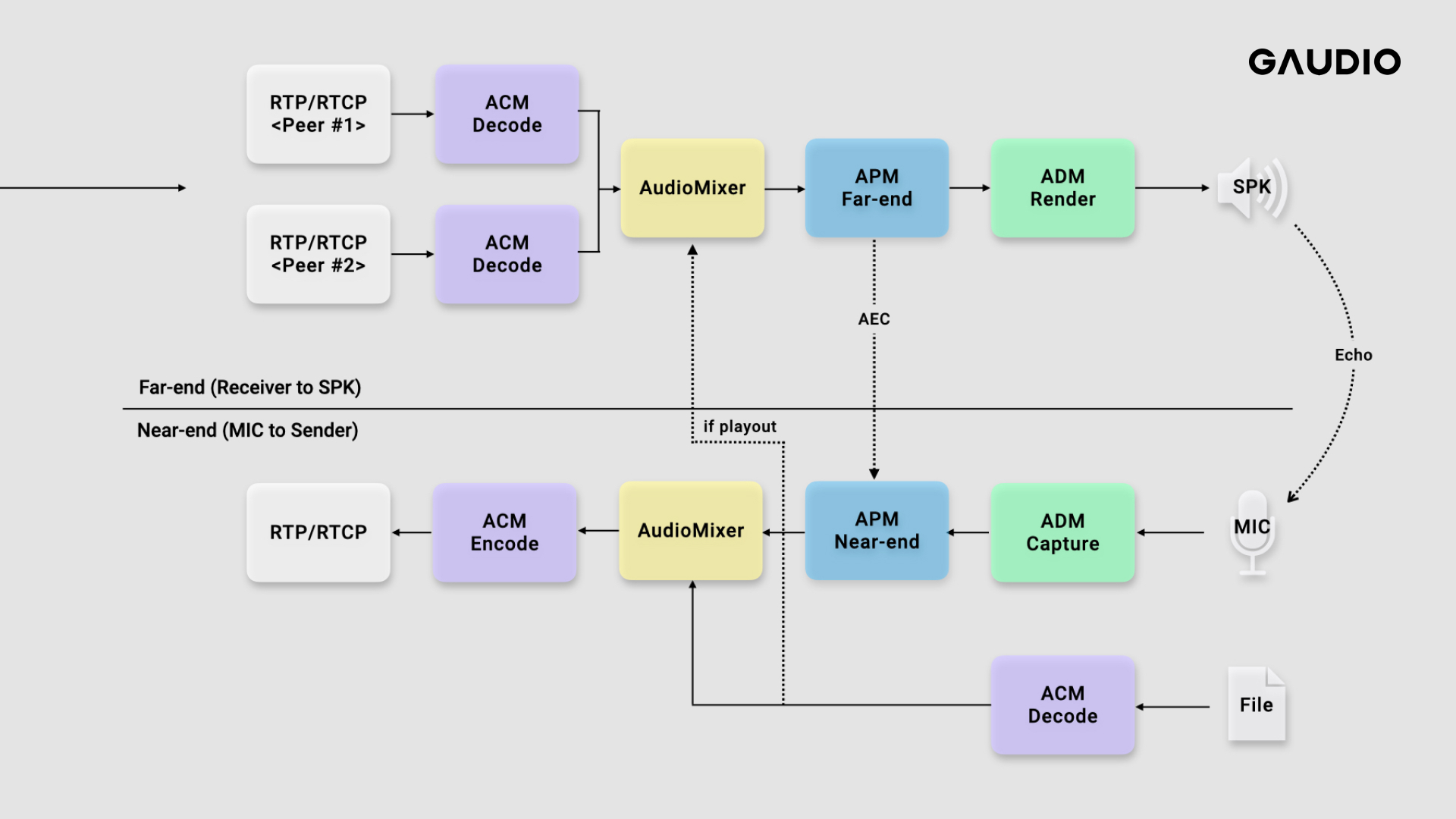
WebRTC Audio 파이프라인과 모듈
설명드린 것처럼 WebRTC의 Audio 파이프라인은 모듈화되어 기능단위로 나누어져 있습니다.
WebRTC의 Audio 품질 개선 w/ Gaudio SDK
가우디오랩에는 GSA(Gaudio Spatial Audio), GSMO(Gaudio Sol Music One), LM1(음량 평준화 TTA 표준)등 훌륭하고 유용한 오디오 SDK들이 많습니다. 이러한 SDK를 탑재된 어플리케이션이나 서비스의 형태로 만들어 사용자에게 좋은 소리 경험을 전달하는 일은 정말 매력적인 일입니다.
(아시나요?) 가우디오랩에는 WebRTC에 찰떡궁합인 SDK가 존재합니다. 바로 AI 기반으로 노이즈 제거가 가능한 GSEP-LD 인데요! 심지어 적은 연산으로 실시간 동작이 가능합니다. (게다가 세계 최고 수준의 성능!)
우리는 화상 회의를 할 때 주변 잡음(노이즈)로 인한 불편함을 참 많이 느끼는데요. 이러한 노이즈를 제거하는 신호 처리 기반의 노이즈 제거 필터가 WebRTC에 포함되어 있습니다. (앞으로 말씀드리겠지만, WebRTC에는 노이즈 제거 필터 이외에도 통화 품질을 높이기 위한 필터들이 이미 존재한다는 사실!) 이 노이즈 제거 필터는 위에서 언급된 APM(Audio Processing Module) 모듈에 포함되어 있습니다.
여기서 기존 신호 처리 기반의 노이즈 제거 필터를 가우디오랩의 인공지능 기반의 노이즈 제거 필터로 교체한다면 효과가 얼마나 좋아질까요? 당장 기존 노이즈 제거 필터를 GSEP-LD로 교체해서 들어 보고 싶은 마음이 앞서지만.., 잠시만요! 이런 복잡하고 거대한 프로젝트에 필터를 통합(혹은 교체)하기 위해서는 마음만 앞서서는 안됩니다. 왜냐하면 마음만 앞서서 무턱대고 통합을 하다보면, 아래와 같은 의문점들이 점점 머리를 복잡하게 만들기 때문입니다.
-
GSEP-LD의 원본의 성능이 잘나오나요? → 원본의 성능이 얼마나 좋은지 확보해야 합니다.
-
기존 신호처리 기반의 필터들과 사이드 이펙트는 없을까요? → WebRTC의 다른 필터들을 제어하며 들어봐야 합니다.
-
최적의 통합 위치는 기존 노이즈 제거 필터의 위치와 같을까요? → 통합 위치를 바꾸어가면서 들어봐야 합니다.
-
다양한 사용자 환경에서 성능을 보장할 수 있을까요? → 다양한 실험 데이터와 플랫폼별 환경이 필요합니다.
마음만 앞서 본 게임으로 바로 들어간다면, 위와 같은 질문들에 휘둘리며 효과적인 통합과 점점 멀어지게 될 것 입니다. 그러지 않기 위해서는 먼저 ‘견고한 테스트 환경의 구축’이 필요합니다. 특히 많은 기술들이 얽혀있는 거대한 프로젝트일 수록, 그 중요성은 더욱 더 높아집니다.
하지만 견고한 테스트 환경을 구축하는 일은 쉽지 많은 않은 일인데요. 이번 글은 WebRTC의 오디오 기술에 대해 설명해드렸다면, 다음 글에서는 제가 WebRTC에서 견고한 테스트 환경을 비교적 간단히 구축해 본, WebRTC Audio 파이프라인에 GSEP-LD을 통합해 성능의 자신감을 높일 수 있었던 경험을 공유할게요!

다양한 디바이스와 플랫폼에 적용 가능한 오디오 기술을 만나 보세요
