AI 가사 싱크? PO가 직접 소개하는 GTS
가사 싱크? AI가 직접 합니다: GTS PO가 직접 소개하는 GTS
(Writer: John Jo)
들어가며 : GTS 소개에 앞서 제 소개를 먼저 할게요.
안녕하세요! 가우디오랩에서 GTS의 PO를 담당하는 존이라고 합니다. 가우디오랩에서는 GTS(Gaudio Text Sync)라는 제품의 PO로, 퇴근 후에는 재즈 보컬리스트로 활동하고 있답니다. 뉴올리언스 마칭밴드인 SoWhat NOLA의 리더이자 보컬을 담당하고 있어요. (막간 홍보)
여러분은 ‘음악을 눈으로도 듣는다 👀’라는 말에 공감하시나요?
바로 노래 가사 이야기인데요. GTS는 요즘 스트리밍 서비스에서 빼놓을 수 없는 ‘실시간 가사 보기’ 기능에 직접 적용되는 제품으로, AI가 자동으로 가사와 음악의 싱크를 맞추는 기능을 제공합니다.
오늘 저는 여러분께 GTS에 대해 소개해 드리고, 저와 가우디오랩이 함께 낳고 기르는(?) 이 AI 제품이 세상을 어떻게 변화시키고 있는지 말씀드리고자 합니다.
‘실시간 가사 보기’의 알려지지 않은 뒷 이야기
오늘 날 대부분의 뮤직스트리밍 서비스가 실시간 가사 서비스를 제공하고 있는데요.
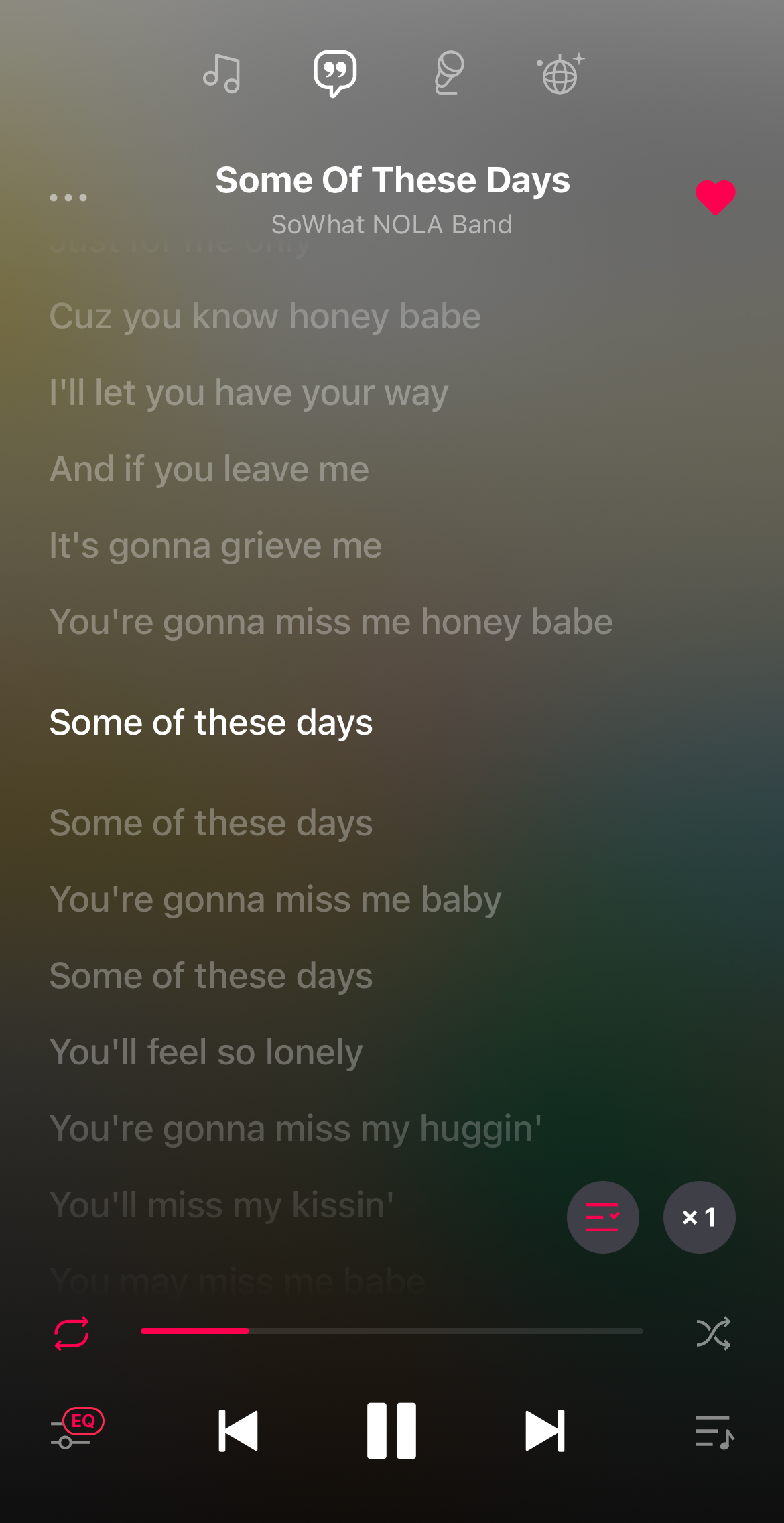
<실시간 가사 서비스의 예시 화면 - 이렇게 말이죠!>
최근까지 뮤직 스트리밍에 인입되는 곡들의 가사와 멜로디의 싱크를 사람이 일일이 들어가며 손수 맞추고 있었다는 사실, 알고 계셨나요? (보통 ‘찍는다’고들 하죠)
사람이 직접 싱크 가사를 만들다 보니 필연적인 단점들이 생기는데요, 아마 우리가 흔히 겪어봤던 일일 겁니다.
-
일단 느립니다. 한 곡 싱크를 위해서는 한 곡 전체를 다 들어야하고 랩처럼 가사가 정말 빠르게 지나가거나 한국어가 아닌 다른 언어가 주 언어가 된다면, 처리 시간은 기하급수적으로 늘어날 수밖에 없죠.
-
퀄리티가 일정하지 않습니다. 위에서 말씀드린 속도와도 연관되는 이야기일텐데요, 싱크가 어려운 음원일수록 시간이 더 오래 걸리기 때문에 하루에 여러 곡을 처리해야하는 담당자들이 모든 곡을 완벽하게 처리하는 것은 불가능에 가깝겠죠.
-
음악 시장에는 하루에도 수 만곡 씩 곡들이 쏟아져 나옵니다. 음악 스트리밍 서비스들이 가사를 싱크하기 위해 인건비를 더 많이 지출해야하는 것은 당연한 일이죠. 게다가 관리 비용까지 생각한다면… 만만한 비용으로 할 수 있는 작업이 아닙니다.
-
아티스트의 문제도 해결합니다. 저도 앨범을 발매할 때 가사 싱크의 문제로 어려움을 겪은 적이 있어요. 재작년에 제 첫 앨범을 발매 했었는데, 해외 스트리밍 서비스(애플뮤직?)에서 실시간 가사 서비스를 제공해주지 않아 제가 직접 한땀 한땀 싱크 작업 서비스를 이용했던 것이 생각나네요. 반면, GTS가 도입되어 있는 국내 스트리밍 서비스에서는 싱크가 잘 맞아 흐뭇해했던 기억이 납니다.
이 문제를 한 큐에 해결하는 AI, GTS에 대해 조금 더 알려드릴게요.
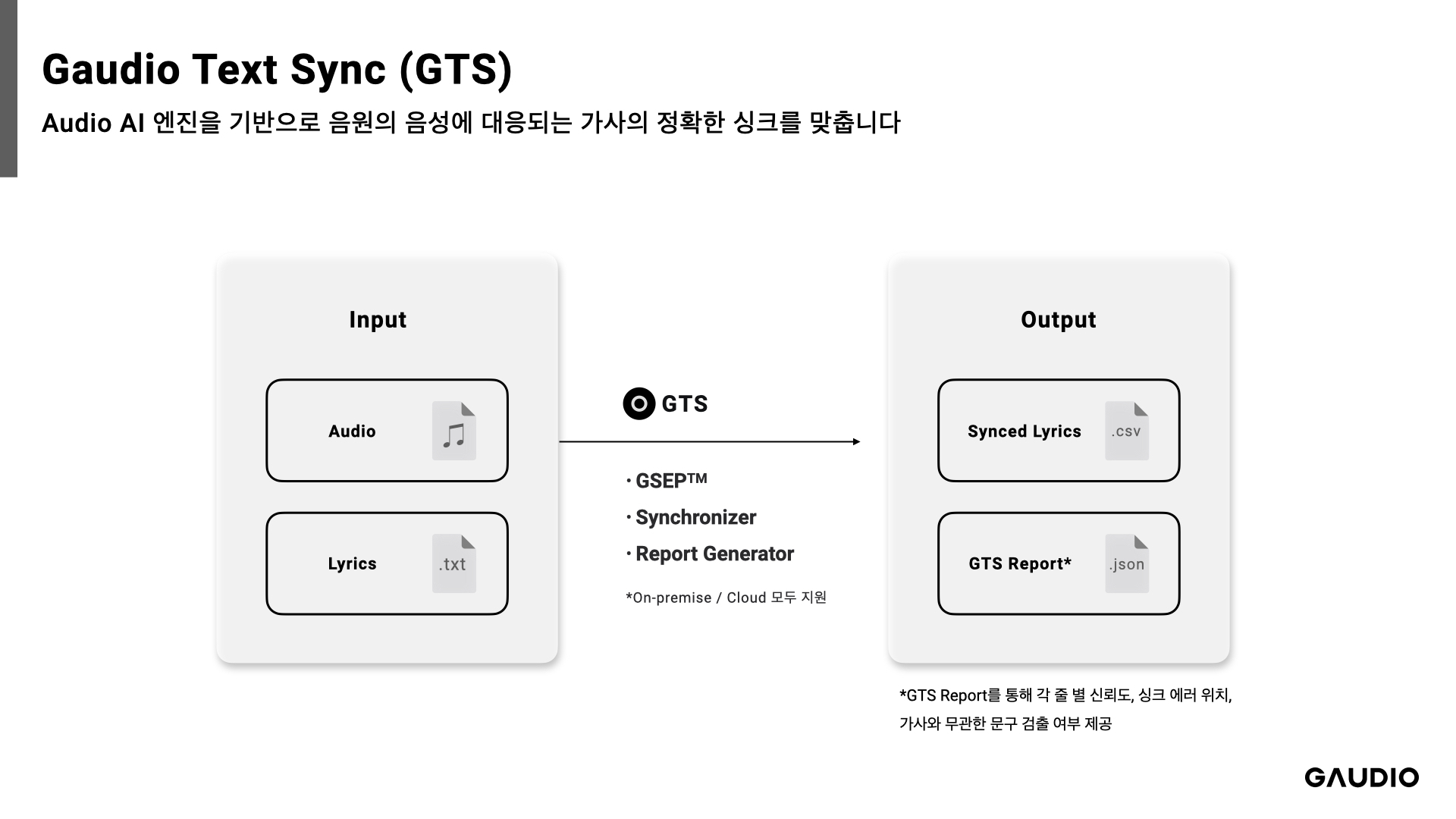
GTS는 Gaudio Text Sync의 약어인데요, 쉽게 말하자면 [AI가 가사와 음원을 자동으로 동기화 해주는 솔루션] 입니다. 예를 들어, BTS의 신곡 “Take Two”의 mp3 파일과 “Take Two”의 가사가 적힌 txt 파일만 있으면 가사들의 타임라인을 자동으로 생성해주죠.
에이 그래도 시간이나 비용이 얼마나 단축되겠어? 라고 물으신다면!
-
GTS는 1곡에 5초면 충분하고 영어, 한국어, 중국어, 일본어까지도 커버합니다. 어떤 곡을 프로세싱하든, 사람보다 월등한 성능으로 정확하게, 그리고 훨씬 빠르게 타임라인을 만들어냅니다. 에미넴이나 아웃사이더처럼 빠른 곡들도 문제 없죠. 이와 유사한 문제를 겪고 있는 스트리밍 서비스라면, 바로 채택할 수밖에 없습니다. (그리고 그게 여러분의 비즈니스에 좋아요!)
-
싱크 결과물 뿐만 아니라 싱크가 얼마나 잘 되었는지, 각 가사의 라인마다 싱크가 잘못 생성이 되지는 않았는지를 담은 곡마다의 ‘싱크 결과 리포트’를 제공합니다. 서비스를 제공 받으시는 분들은 해당 리포트를 가지고 잘못된 가사나 싱크를 손쉽게 검토하고 수정할 수 있죠. (퇴근시간이 빨라져요!)
-
이제 한국 뮤직 스트리밍 서비스 대부분은 GTS를 통해 만들어 낸 실시간 가사를 고객들에게 제공하고 있습니다. 해외의 스트리밍 서비스들도 눈독을 들이고 있고, 계속 긴밀한 미팅을 진행 중에 있습니다. 한국은 잡았고, 해외로 갑니다! 부릉!
-
하지만 아직 놀라긴 일러요. 가사의 줄 별 타임라인을 만들어내는 것부터 시작한 GTS는 이제 어절 별 타임라인까지 찍어내기 때문이죠. 기술의 고도화를 통해 이제 어절 별을 넘어 노래방에서 볼 수 있는 글자 별 타임라인까지 생성하는 것을 로드맵으로 리서치팀, 개발팀과 함께 움직이고 있습니다.
백문이 불여일견, 한 번 비교 해봅시다.
한국의 음악 스트리밍 플랫폼인 G사와 NAVER VIBE의 가사 싱크를 함께 볼까요?
제가 좋아하는 Incognito라는 그룹의 Still a friend of mine 이라는 곡을 골라봤어요.
먼저 G사의 실시간 가사보기 화면인데요, 싱크가 거의 1줄 이나 차이나는 걸 보실 수 있죠.
다들 이런 경험 있으실거예요. 참 답답하고 불편하죠. 해당 가사를 눌렀을 때 딱 그 구간으로 이동해서 듣는 데도 어려움이 있고요.
그리고 아래는 GTS를 적용한 VIBE입니다.
싱크가 잘 맞아 음악을 즐기기에 훨씬 좋네요. (바이브의 전매특허, 원어민 급 자연스러운 번역 가사를 볼 수 있는 것은 덤!)
GTS는 세상을 이렇게도 바꾸고 있어요
이은교육: 청각 장애인들도 음악을 들을 수 있어요.
GTS는 청각 장애인용 음악 교육 서비스에도 쓰입니다. 어절 별 진동을 통해 청각 장애인에게도 음악을 향유할 수 있도록 하는 건데요. 이 어플리케이션의 런칭을 준비하고 있는 한국의 이은교육에서도 GTS가 활약하고 있습니다. GTS가 어절별 시작 점과 끝 점 타임라인을 도출하는 과정에 쓰여 청각 장애인들이 가사의 마디 마디를 구분할 수 있도록 돕습니다. 훌륭한 AI 기술을 통해 세상을 더 좋게 만든다는 가우디오랩의 미션을 실천 중이지요.

<이은교육과의 미팅>
콘샐러드: 인디 뮤지션도 쉽게 리릭 비디오(가사 비디오)를 만들 수 있어요!
콘샐러드에서는 인디 아티스트들의 신곡 홍보를 위해 리릭 비디오(Lyric Video, 아래 그림 참조)를 만들어 배포를 하고 있는데요. 이 리릭 비디오의 가사 싱크를 위해 GTS가 이용되고 있기도 합니다. 가우디오랩의 기술로 인디 뮤지션들의 홍보를 돕는 것이죠.
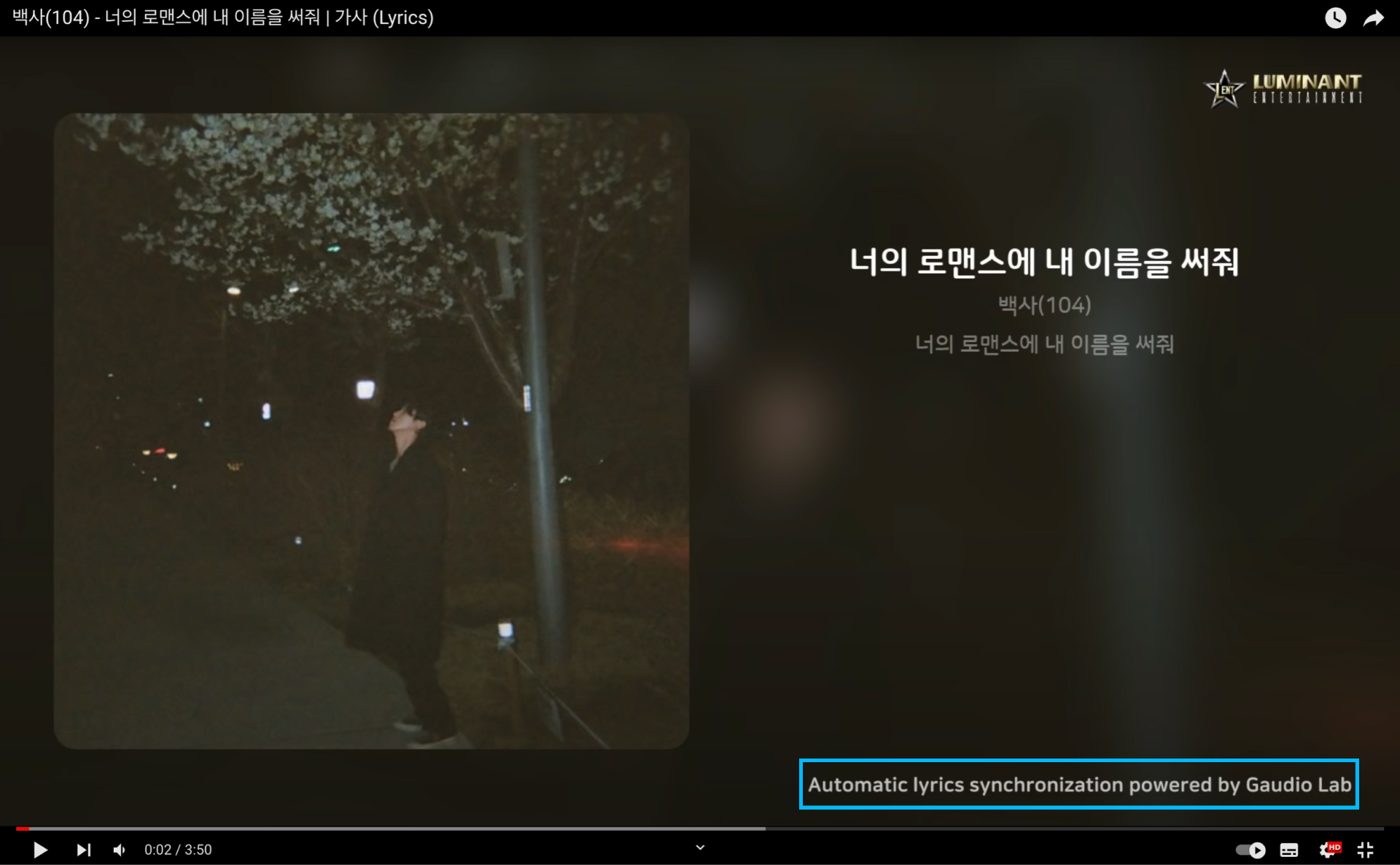
다시 한 번 가우디오랩의 미션인 ‘혁신적인 기술로 사람들에게 훌륭한 소리경험을 제공한다'를 실천 중인 사례라고 볼 수 있겠죠?
여기서 멈추지 않습니다. 무궁무진한 GTS의 세계…
-
텍스트와 음성의 싱크가 필요한 곳이면 전부 가능합니다.
-
OTT나 영상의 폐쇄자막과 음성의 싱크가 필요할 때
-
오디오북에서 오디오와 텍스트의 싱크가 필요할 때
-
어학학습을 위해 오디오와 텍스트의 싱크가 필요할 때
-
-
그 외에도 GTS가 적용될 수 있는 곳은 생각보다 세상 곳곳에 많이 있으니, 언제든 저를 찾아주세요 🙂
끝 맺으며
제가 가우디오랩에 합류해서 제일 먼저 한 일은 바로 GTS의 상용화였습니다. 이제는 GTS가 한국 대부분의 뮤직스트리밍에서 쓰이는 제품이 되어 많은 유저들이 더욱 풍성하게 음악을 들을 수 있도록 기여하고 있으니 정말 뿌듯한 마음입니다.
제 다음 타겟은 한국 외의 모든 시장들입니다. 전 세계의 수많은 음악/OTT 등 스트리밍 서비스에 GTS가 적용될 수 있게 박차를 가할 예정입니다.
한국을 넘어 전 세계 유저들의 청취 경험을 개선하고 싶으신 분들, 어서 가우디오랩의 문을 두드리세요! 🙂

다양한 디바이스와 플랫폼에 적용 가능한 오디오 기술을 만나 보세요
