Behind the Scenes: How We Built the Just Voice Recorder, a Noise-Reducing Recording App
On May 20th, Gaudio Lab released the AI noise-cancelling recording app 'Just Voice Recorder' on the App Store. Was it because it featured AI noise removal, which is not common in recording apps? The app was highly anticipated from pre-orders and had a successful debut on the App Store.
Today, we'd like to share an interview with Jin, the PO of the Just Voice Recorder app, to give you a behind-the-scenes look at the app's development process, as well as tips for better use of the Just Voice Recorder app.
Q. Can you start by introducing yourself?

Hello, I’m Jin, the PO of the Service and App (SNA) team at Gaudio Lab. I have about 8 years of experience as a PO/PM in various industries before joining Gaudio Lab.
Q. How do you feel about launching your first mobile app after joining Gaudio Lab?
I’m very proud, of course. Thinking back on all the hard work, it feels very rewarding. While I’m happy, I also have some regrets. Due to various constraints, I feel like we couldn’t fully meet all the needs. We plan to address these through continuous updates.
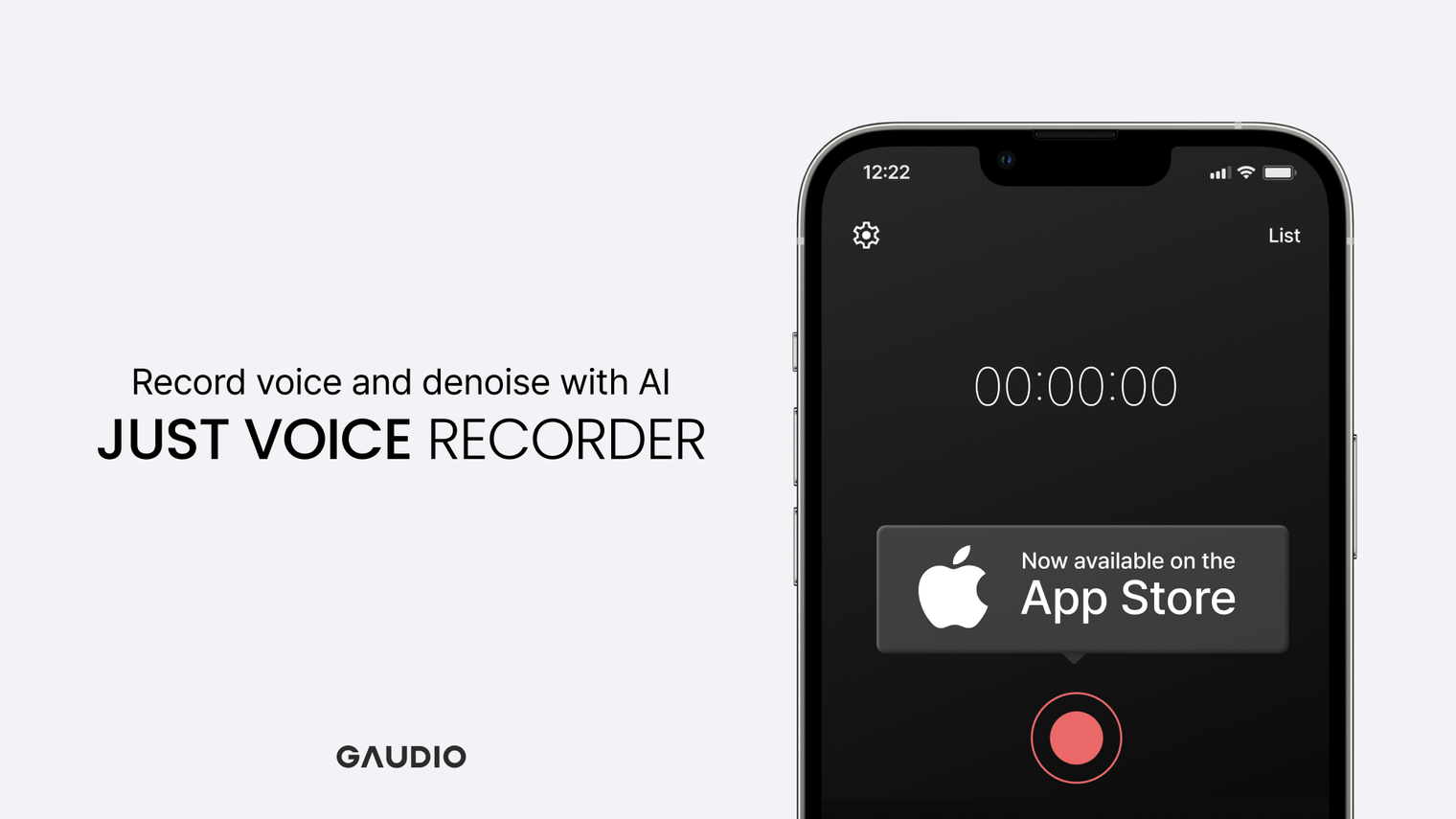
Q. What kind of app is Just Voice Recorder?
Just Voice Recorder is a recording app with powerful noise-canceling AI technology from Gaudio Lab. It removes background noise, allowing you to hear voices clearly even in noisy environments. Moreover, the noise-cancelling AI in Just Voice Recorder operates on-device without sending recording data to the server, making it secure for personal recordings.
Q. Who should use Just Voice Recorder?
Anyone who needs to record can use Just Voice Recorder. Regardless of time or place, you can record and then process noise or volume issues through Just Voice Recorder.
To be more specific, I recommend it for students who record a lot of lectures, or for creatives and journalists who record a lot for their jobs. If you're a student, you can remove keyboard noise, air conditioner noise, etc. from your lectures to make sure your recordings from the back of the room are clear. If you're a creator, you can capture your voice clearly anytime, anywhere, without the need for specialized equipment.
Q. How did Just Voice Recorder get started?
What’s the story from the initial idea to the decision to create it?
The idea began with ‘Let’s create a mobile app using *GSEP-HQ technology.’ GSEP-HQ is a technology used to separate instruments or vocals from audio tracks, widely loved and used in Gaudio Studio. However, Gaudio Studio is a web service that runs on servers. We wanted to implement it in a mobile app to align with the current trend of on-device AI. We chose to develop a recording app, believing it was the most straightforward (though it wasn’t easy) and valuable for users.
*GSEP: Developed by Gaudio Lab, GSEP is a sound separation technology. It includes GSEP-LD, capable of real-time processing, and GSEP-HQ, which offers higher quality sound separation. You can experience GSEP-LD through Just Voice Lite. (Learn more about GSEP)
Q. What is the biggest value that Just Voice Recorder offers?
The main goal of Just Voice Recorder is to solve real user problems. While there are many recording apps, few address issues like noise during recording or inaudibility. We believed Gaudio Lab’s GSEP-HQ technology was suitable for solving these unmet needs, providing a good fit between the technology and the problem.
Q. If you had to choose the most important feature of Just Voice Recorder, what would it be?
I would say it’s the noise cancellation based on powerful audio separation technology. Although the default iPhone recording app has a noise reduction feature, Just Voice Recorder excels at removing really disruptive noise.
However, there’s still room for improvement, especially in separating voices when the background noise is louder or the recorded voice is faint. We’re continually working on enhancements.
Q. You mentioned there were many challenges during app development.
Can you share a memorable episode?
The process of deciding on the AI model for noise cancellation stands out. Initially, GSEP-HQ wasn’t ready for mobile use. We used the Just Voice SDK for development and planned to switch to GSEP-HQ once ready.
However, we faced challenges because Just Voice SDK could process in real-time using CPU, while GSEP-HQ required GPU and had longer processing times, making real-time processing impossible. This led to a prolonged decision-making process, requiring us to develop for both simultaneously. We later reflected that quicker decisions could have led to more efficient development.
Q. Why was the app released only for iOS and not Android?
Although over 60% of pre-registrations were from Android users, we faced significant UI performance issues unique to Android due to high GPU usage during the GSEP-HQ model implementation. This structural difference between Android and iOS led us to prioritize the iOS release.
Q. What’s next for the Just Voice Recorder app?
We have many features we’d like to add, such as adjusting background noise volume during export, STT (Sound to Text), and recording file editing. We’re also considering expanding to iPad and Apple Watch
However, I believe it's more important to prioritize the basics of the app, particularly the best noise removal and stable app operation.
The first issue we want to improve is the long wait time for noise removal. Using Just Voice SDK can solve this, but we chose performance over speed because the value of Just Voice Recorder lies in top-level noise removal. We're monitoring user reactions to find the sweet spot between speed and performance and improving the model to enhance speed accordingly.
Another issue is the decreased separation performance for faint voices. This is an inherent limitation of the GSEP-HQ engine developed for instrument separation. We're working with the R&D team to overcome this limitation and plan to implement solutions in Just Voice Recorder as soon as possible to ensure it can cleanly separate voices of any volume.
Q. It’s been about a month since the app launch.
How would you summarize the experience so far?

I would like to take this opportunity to thank all of the Gaudins who stepped up to the plate and helped us finish this project, despite the many challenges we faced.
One of the biggest questions we had while developing Just Voice Recorder was, "Is this app solving a real problem that users are experiencing?" It's still a difficult question to be sure, but since we've put the app in front of users, I think we can only find the answer by looking at user reactions and analyzing data.
I also think it's a great achievement to see that Gaudio Lab's technology can be fully utilized in mobile and B2C environments.
🎙️ In conclusion…
From Just Voice Lite for Mac to Just Voice Recorder, our iPhone app, GaudioLab continues to push the envelope to deliver innovative sound experiences wherever there is sound.
We had a candid interview with Jin, our PO, to learn more about the development of the Just Voice app, from its beginnings to its limitations, and we hope you're curious about the ever-evolving Just Voice Recorder app.
If so, head straight to the app store and download it via the link below. A new world of recording awaits you! >> https://apps.apple.com/app/just-voice-recorder/id6479693805


Our audio technologies support various devices and platforms.
