Gaudio Studio – Your favorite songs, as you’ve never heard them before
Gaudio Studio – Your favorite songs, as you’ve never heard them before

Last year, MusicRadar reviewed five of the most popular stem separation software tools that are available today, and Gaudio Studio emerged as winner of the battle against Serato Sample, Acon Digital, DeepRemix and FL Studio. To the judge’s surprise, the champion was the only one free. We are honored that Gaudio Studio’s first overseas coverage has such a flattering review, as well as valuable feedback, and believe it’s a good time as any for its official introduction by Gaudio Lab.
Gaudio Studio is our web-based AI sound source separation service, powered by cutting-edge audio AI models. Currently under beta, Gaudio Studio offers two features that are fun and easy for anyone to use and still performs frighteningly well:
-
Instrument Separation – A stem separation tool that can isolate vocals and instruments from any music that you want
-
Noraebang – An instant karaoke maker with vocal separation and lyrics synchronizing capabilities, title after the Korean word for karaoke.
Audio Stem Separation
Before we go on, what is stem separation? While sound source separation refers to the general practice of eliminating or extracting desired sounds from the original audio, stem separation refers to the more specific task of isolating sounds of individual tracks, or ‘stems’ from a mix. The conventional problem definition in the modern music industry is the separation of four stems, namely the vocals, bass, drums and other instruments, for their ubiquity and distinction in character.
Traditionally, stem separation relied on signal processing techniques using manually crafted features and were mostly limited for use in simple audio scenarios. However, recent advancements in artificial intelligence have opened up the possibility for stem separation of more complex tracks with many instruments and diverse tones. Given enough training data, deep learning models can be trained to distinguish the intricate patterns of different instruments autonomously and adaptively.
But even with deep learning, designing a well-performing stem separation model is no walk in the park, and many AI-based programs available today still produce results mixed with artifacts and distortions. This is especially so for mixes with multiple instruments masking each other in terms of timbre and loudness. In fact, it is often very much a challenging task even for humans to do with untrained ear, let alone for AI.
GSEP and Instrument Separation
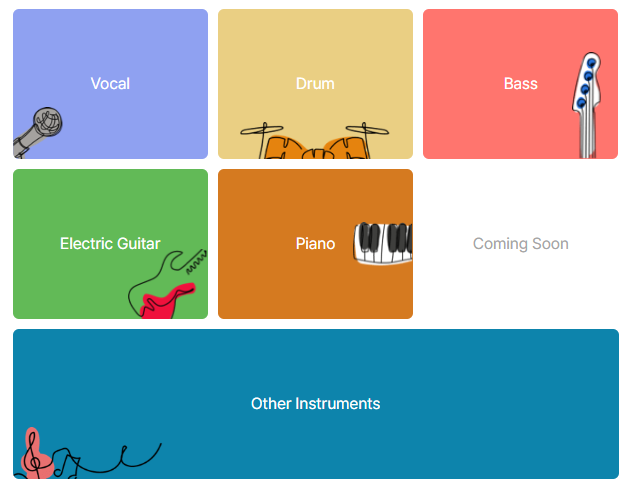
Gaudio Studio’s Instrument Separation provides one of world’s most reliable – if not the most reliable – stem separation service out there, as tested and approved by our users each and every day. With a simple utility, the current version supports isolation of up to 6 instruments for the music of your choice, including electric guitar and piano on top of the aforementioned four-stem system. The other unselected or undefined stems are all tied up into the Other Instruments stem. After the instruments are chosen, the separation request is loaded to a queue and the processed results become available for playback and download.
At the core of the technology is Gaudio Lab’s AI separation model GSEP, short for Gaudio source SEPeration, which boasts state-of-the-art performance that has outshined its competitors since its release in 2021. Developed with utmost attention to greater sound quality, GSEP delivers clean and natural separation results that are often indifferentiable from stand-alone studio recordings. Compared to other AI separation solutions, some of the most common issues that plague sound quality such as over-suppression (muffled sounds) and loudness inconsistency (fluctuations) are rarely heard. Of course, readers are welcome to listen for themselves, either by trying out with their own examples or checking out some of the comparisons already made by other users, like this one.
Sure, GSEP sounds good (no pun intended). But it has also surpassed many other stem separation models under objective criteria, having reached an SDR (Signal-to-Distortion Ratio) of 10 dB for vocals and 16 dB for accompaniments in a 2021 external evaluation. Here, SDR is a key metric commonly used for audio separation. It measures the amount of undesirable distortions in the result in comparison to the ideally separated signal. For reference, every 10 dB increase in SDR means that the distortions of the results are 10 times less significant. While this in itself implies that GSEP’s record is an impressive feat, it also means that GSEP scores even higher than the latest version of Meta’s Demucs.
Behind GSEP’s exceptional quality lies Gaudio Lab’s sincerity and passion for audio in general. Not only are our AI team members also audio enthusiasts, but they create a special synergy with our Audio team, strongly based in audio signal processing, for applying deep learning within the domain of sound. Together they decide what kind of psychoacoustic considerations, additional databases and model architecture would lead to more versatile and reliable audio separation. GSEP is continually refined by our developers with ongoing training aimed at not only achieving higher SDR but also actual superior sound quality, ensuring that the results meet the highest standards at the perceptual level.
GTS and Noraebang
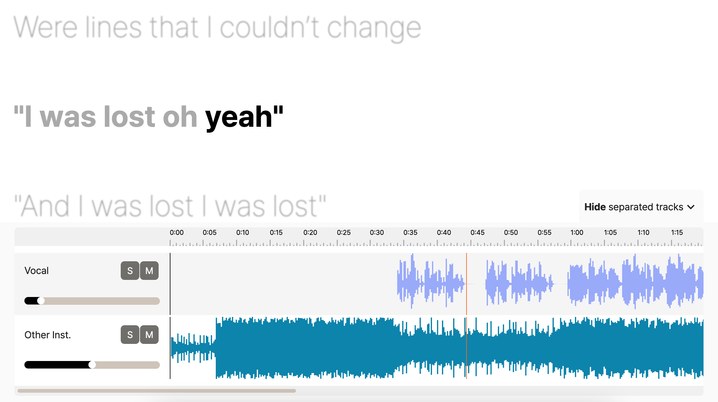
GSEP’s clean vocal-accompaniment capabilities naturally led to the idea of a karaoke backing track generator. Together with an automatic lyrics synchronization technology, the idea was soon developed and implemented as Gaudio Studio’s Noraebang. With it, all you need to do is upload a music of your choice along with its lyrics, and the rest of the karaoke experience is set up by the AI engine. The web interface of Noraebang displays the synchronized lyrics highlighted word-by-word in precise timing with the music playback, delivering a karaoke experience accessible from any device.
Working in tandem with GSEP under the hood of Noraebang is Gaudio Lab's GTS – Gaudio Text-Synchronization – a robust tool for aligning speech audio with corresponding text. While the challenge of first identifying vocals within complex musical structures is rendered trivial with GSEP’s sound separation capabilities, GTS handles the remaining problem of correlating and generating time stamps between the speech information and the natural language text.
GTS is an adaptable AI model that is designed to be robust against across different rhythmic styles, tempos and vocal nuances. A part of its adaptability comes from its indifference to the specific language of the text, as it is not trained to recognize the sounds of individual languages, but rather the sounds of phonemes that match with the International Phonetic Alphabet (IPA). Simply put, all GTS needs in order to learn a new language is its pronunciation scheme using a dictionary of words tagged with their IPA symbols, a well-documented data for most common languages.
GTS achieves highly consistent results independent of the song’s genre or artist, but without compromise in speed and quality. Processing long text and audio sequences requires high computation cost and time. GTS’s model deals with this problem by adopting a hierarchical structure in which alignment predictions are first made at sentence level, then recursively at word level. This allows inference time of under 5 seconds to synchronize an entire song and an impressive accuracy of around 99% regardless of the song’s length and complexity.
Using Gaudio Studio Beta
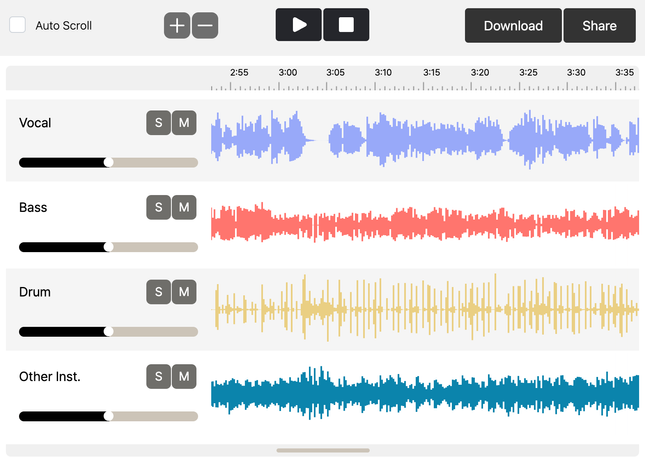
So, you can use Instrument Separation and Noraebang to create and share isolated tracks on a whim and even instant karaoke versions of your favorite songs. Of course, no worries even if the music of your choice is instrumental only – GSEP is trained on individual stem types and faithfully works on those requested by the user.
Another reason why Gaudio Studio is so useful is that you can use its services wherever you want, however you want. It supports audio inputs from lossless to compressed formats (including flac, wav, mp3 and m4a), as well as video files video urls without the need of conversions or downloads. Since Gaudio Studio is accessible through either PC or mobile devices, it is as easy to use for casual mobile users who want to try out a few songs for fun, as it is for more serious hobbyists and musicians who want to process batches of high-quality samples in their desktops.
Despite all that, Gaudio Studio is still under beta and there are a few limitations. While GSEP and GTS are frontrunners in their fields without a doubt, there is much room for improvement with corner cases and functionalities. Our developers are not satisfied short of perfect and are constantly investigating and logging points of improvement and tweaks. Users may also feel that they currently have to wait a bit too long for their requests to be processed and may wish to download the results in a higher quality format than mp3. We want to assure fans and supporters that future updates are under way and that they can look forward to added stem options, higher performance and better utility.
Try for yourself.
At Gaudio Lab, we love to hear how the users of Gaudio Studio apply stem separation in so many diverse ways, from simplifying transcription tasks by separating individual instruments to crafting personalized backing tracks for practice sessions, and even extracting unique samples for homage in new compositions. Now and then, we are pleasantly surprised when we come across use cases that we could not have imagined.
What would you do with Gaudio Studios’s AI sound separation technology?
Try it out for yourself! We are eager to find out.

Our audio technologies support various devices and platforms.
