Patently Gaudio #1 - Phase-matched Binaural Rendering
The Importance of Uncompromised Sound Quality:
Gaudio Lab’s Solution to Sound Quality Distortion in Spatial Audio
At Gaudio Lab, we tackle the world’s audio challenges with software products that incorporate innovative audio source technology and make people's lives better. The term ‘source technology’ implies that Gaudio Lab is a hub of originality. One method we use to share our innovations with the world is through patents. Many of our core technologies are protected this way, and we hold a substantial number of patents, especially considering our company’s size and years in operation. However, sometimes we may strategically decide not to patent certain technologies, despite their originality.
A patent is a system granting inventors exclusive rights for a certain period (typically 20 years), in exchange for making their technological advancements public. After this period, the technology becomes openly available, making it easy for competitors to imitate. The responsibility to prove any unauthorized use or infringement of the technology mainly falls on the patent holder. In cases where proving infringement is challenging, it might be more advantageous for us not to disclose the technology. This approach may seem at odds with the advancement of humanity, but for a company focused on profit, freely sharing extensive research and development is a tough decision. Nonetheless, we at Gaudio Lab have filed over 100 patents since we started, a noteworthy achievement even for a company driven by technology.
You can find a list of our publicly disclosed patents here: https://www.gaudiolab.com/company/patents
They can also be explored in detail through a simple Google search. However, for those not in the field, understanding these patent documents can be quite difficult. Therefore, we have decided to make our patents more approachable. We plan to explain them in simpler terms, focusing on (1) the problems we aimed to solve, (2) the main ideas of our inventions, and (3) the benefits these inventions bring.
After careful consideration, Gaudio Lab decided that the first topic to discuss from our extensive portfolio of over 100 patents would be on Spatial Audio. This is a field where we consider ourselves to be the original experts. More specifically, we focused on the crucial technology of Binaural Rendering in headphones (earbuds). Despite narrowing down our focus, there were still over 50 patents to choose from. It’s important to note that all our patents are significant (if they weren’t, we wouldn’t have invested the time and expense in filing them). Each patent is highly valued, much like a cherished child, filled with the inventors’ hard work and dedication. While this series will eventually cover all of our patents, the first episode is always critical.
The first patent we chose to discuss is US 10,609,504 B2 (Audio signal processing method and apparatus for binaural rendering using phase response characteristics). To help make understanding patents easier, let’s start with how to read the unique number of this patent. ‘US’ indicates that it is a United States patent. Other countries use two-letter codes like KR for Korea, CN for China, and JP for Japan. The ‘B2’ shows that this patent has been ‘granted’, meaning it has been reviewed and recognized by the United States Patent and Trademark Office. Patents that are still under review and not yet granted are marked with symbols like A1/A2. The number ‘10,609,504’ is the serial number assigned by the US Patent Office, suggesting it’s approximately the 10,609,504th patent since the patent system was established in the United States. Back in Edison’s era, patents were numbered in the tens to hundreds of thousands. The text in the brackets is the title of the invention. Sometimes this title clearly describes the invention, while other times it can be vague or less helpful, and this is often intentional. The title does not limit the rights of the patent, allowing some freedom in its wording.
This patent also has been filed and registered in KR, CN, and JP, with the following equivalent patents:
- KR 10-2149214 (Audio signal processing method and apparatus for binaural rendering using phase response characteristics)
- CN 110035376B (使用相位响应特征来双耳渲染的音频信号 处理方法和装置)
- JP 6790052 B2 (位相応答特性を利用するバイノーラルレンダリングのためのオーディオ信号処理方法及び装置)
The full texts of these patents are available at the following link.
For US patents, visit: https://patents.google.com/patent/US10609504B2/en?oq=US10609504B2
These patents are collectively known as family patents. As patent laws vary by country, securing global protection for an invention requires separate applications and registrations with each country’s patent office. The recognition of a technology and the extent of rights it receives can differ from one country to another, and even among examiners within a patent office. As a result, the same technology might have a different scope of rights in various countries, and in some instances, it might not get registered at all.
Now, let’s look more closely at what the patent entails.
[The Problem Addressed by the Invention]
Binaural rendering, a method for producing spatial sound through headphones, involves adding a filter known as HRTF (Head-Related Transfer Function) to the audio signal. For a detailed overview of the binaural rendering technology, please see this link. However, often it’s necessary to apply not just one, but several filters simultaneously. An HRTF is a filter linked to a specific point in space. For example, if the sound of a sparrow corresponds to one point, then the roar of an elephant might be associated with a broader area, requiring multiple HRTFs to accurately depict this sound. Similarly, if a sound reflects off a wall and reaches our ears, it would need different HRTFs for the original and reflected sounds, as they come from different directions. Furthermore, if the impact of the HRTF is too strong (which might mean a significant change in sound quality) and needs to be softened, the process of softening also requires a filter, leading to the use of multiple filters.
In real-world applications of binaural rendering, there are many situations where applying multiple filters to a single sound source becomes necessary. This is not exclusive to binaural rendering; in general, adding effects to audio often involves the complex use of multiple filters.
What issue arises when multiple filters are superimposed? Different time delays (Delay) for each filter, as the input audio signal passes through, can unintentionally distort sound quality, known as the 'Comb Filter' Effect. This term comes from the pattern that appears on the frequency spectrum, resembling the teeth of a comb, where certain frequencies are significantly amplified and others are notably reduced, altering the original sound dramatically. It typically occurs when signals pass through two filters with disparate delays.
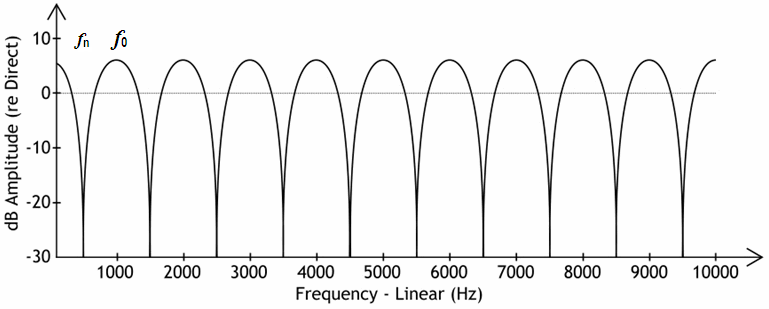
Fig.1: Example of the comb filter effect
(image source: http://www.sengpielaudio.com/calculator-combfilter.htm)
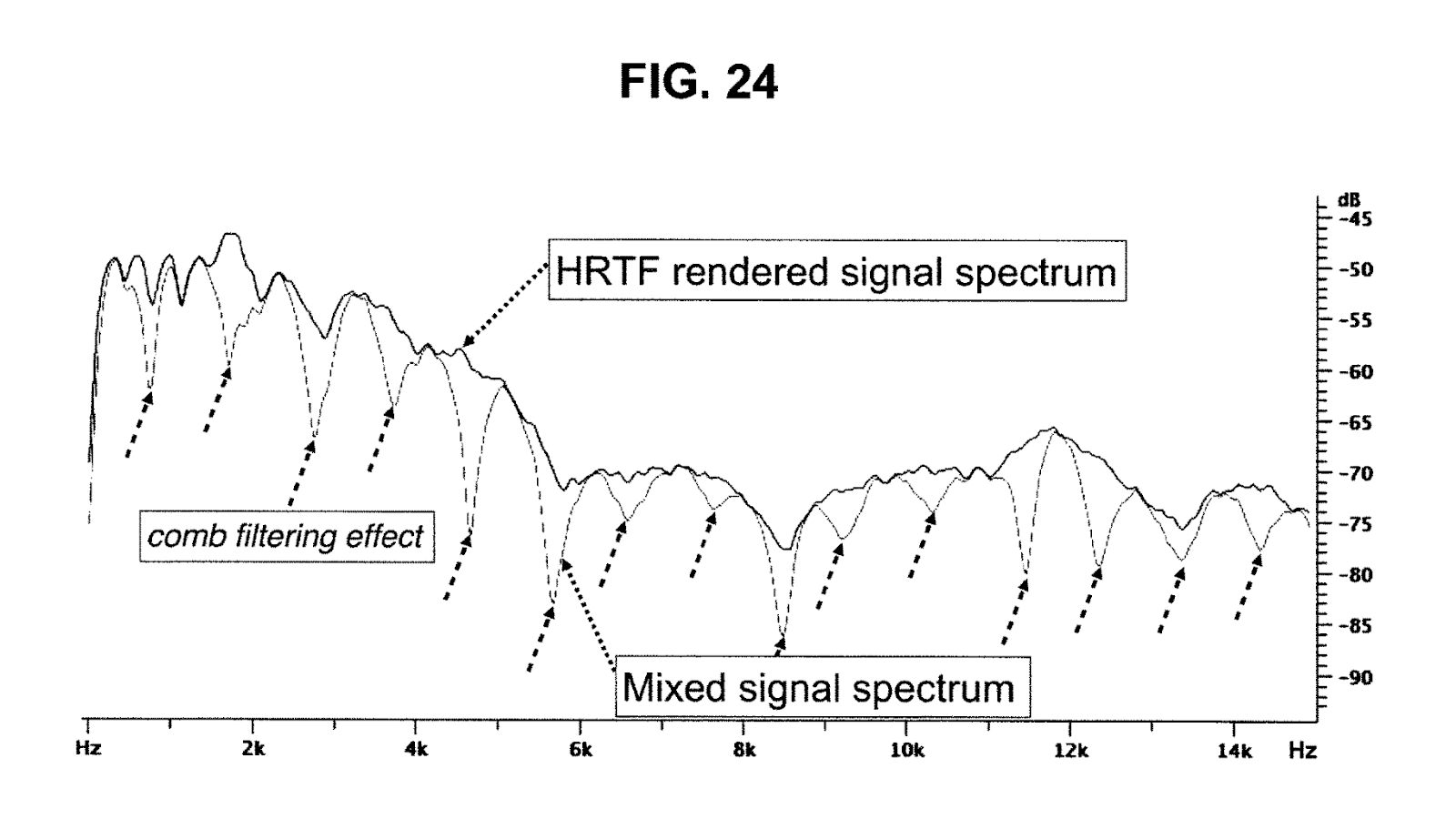
Fig.2: An example of the comb filter effect – Periodic distortions that mimic the appearance of a comb’s teeth emerge in the frequency response
(Referenced from Fig. 24 of patent US 10,609,504 B2)
It would seem that if we could just align the delays of the multiple filters we plan to use in parallel, there would be no issue. And that is a valid point. However, there’s an added complexity when it comes to HRTFs. A HRTF is a filter that’s obtained by measuring sounds played from various directions using microphones placed in human ears or a mannequin. Despite precise measurements, slight variations in delays between filters are unavoidable due to measurement errors that can arise from many factors. These variations cause slight differences in delay at each frequency of the filter response, leading to the unintentional comb filter effect when multiple HRTFs are used in parallel, which can degrade the audio quality.
This patent was developed to overcome this specific problem.
[The Fundamental Concept of the Invention (Subject Matter)]
Identifying the problem clearly can sometimes lead to a surprisingly straightforward solution. This is the situation with the problem this invention addresses. Since the central issue is the varying delays across each frequency of each HRTF filter, the core idea, or the Subject Matter, of this invention is to “align them uniformly.” Up to this point, we have used the term delay for clarity, but in signal processing (Signal Processing) terminology, this becomes a value known as phase (Phase) on the frequency axis. To align this phase response linearly (Linear) means setting a consistent delay, and by ensuring this fixed delay is the same for every filter, we can eliminate the comb filter distortion. Below is a graphic representation showing the phase response of the original HRTF before and after this linearization process.
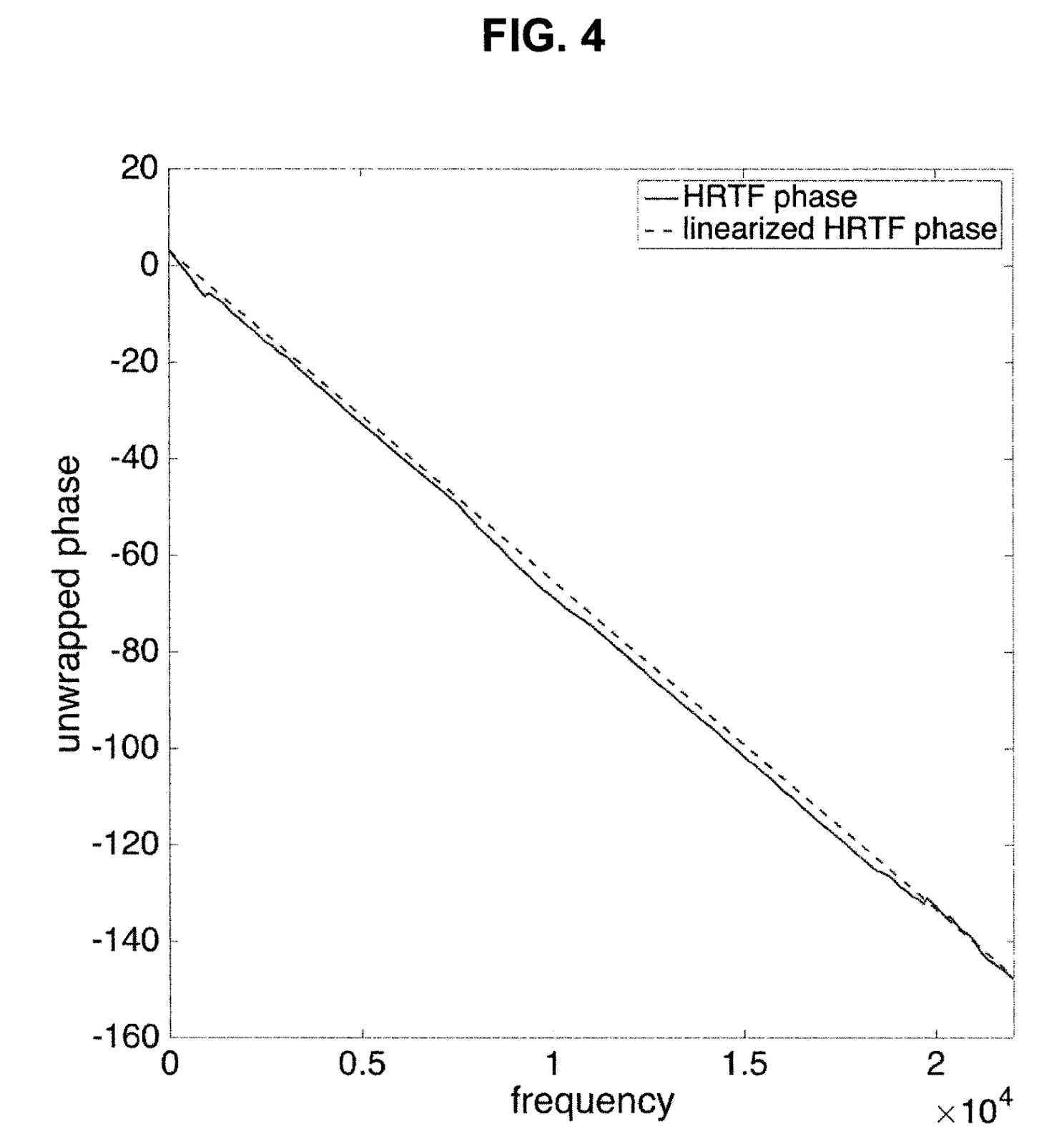
Fig.3: Fig. 4 from U.S. Patent US 10,609,504 B2 – Demonstrates the phase response of the original HRTF alongside the linearized phase response
Integrating the concept of linearization into HRTFs involves a significant issue. HRTFs consist of filter pairs that represent the acoustic paths from the sound’s origin to both ears. The spatial effect of the sound depends on the relative relationship of these filter pairs, which includes their phase responses. If we linearize each filter within a pair without considering this relationship, we would alter their inter-aural phase difference (IPD), a key element in spatial perception. Such an alteration could lead to a loss of the spatial effect, which is central to HRTF functionality. To address this, the invention suggests linearizing only one filter of each pair and adjusting the phase of the other to maintain the IPD.
The filters in an HRTF pair are distinguished as ipsilateral HRTF for the nearer ear and contralateral HRTF for the farther ear. Since the ipsilateral HRTF captures more energy (sound is perceived as louder by the nearer ear), the method involves linearizing the phase response of the ipsilateral HRTF.
[Impact of the Invention]
This method allows the layering of any number of HRTFs without the issue of comb filter distortion. It significantly reduces one of the most prevalent challenges in spatial audio production: preserving the integrity of the original sound quality.
Spatial audio is a technology that simulates the effect of sounds as if they are occurring in a real space, making it essential for applications like gaming, films, virtual/augmented reality, and Spatial Computing. Imagine creating the illusion that you’re in your room, yet feeling like you’re at a Taylor Swift concert in Carnegie Hall – this is often described as the “Being There” Experience. However, the application of HRTFs inherently alters the original sound, as it involves applying a transformative filter, leading to distortion as we’ve discussed. Thus, the quality of spatial audio technology hinges on its ability to minimize such distortion while delivering a lifelike auditory experience. The technology from this invention is expected to be increasingly important in this respect.
We have made an effort to thoroughly explain a core component of Gaudio’s spatial audio technology. We hope that you have gained some understanding of our commitment to crafting high-quality spatial audio experiences. Gaudio Lab is excited to continue showcasing our dedication to exceptional sound experiences through our patents, and we invite you to stay engaged with our future updates.

Our audio technologies support various devices and platforms.
