Audio Quality Evaluation of Spatial Audio Part 2: Evaluation Result - GAUDIO vs Apple
Audio Quality Evaluation of Spatial Audio Part 2: Evaluation Result - GAUDIO vs Apple
(Writer: James Seo)
Evaluation Result
The results obtained from the previously described evaluation process are as follows:
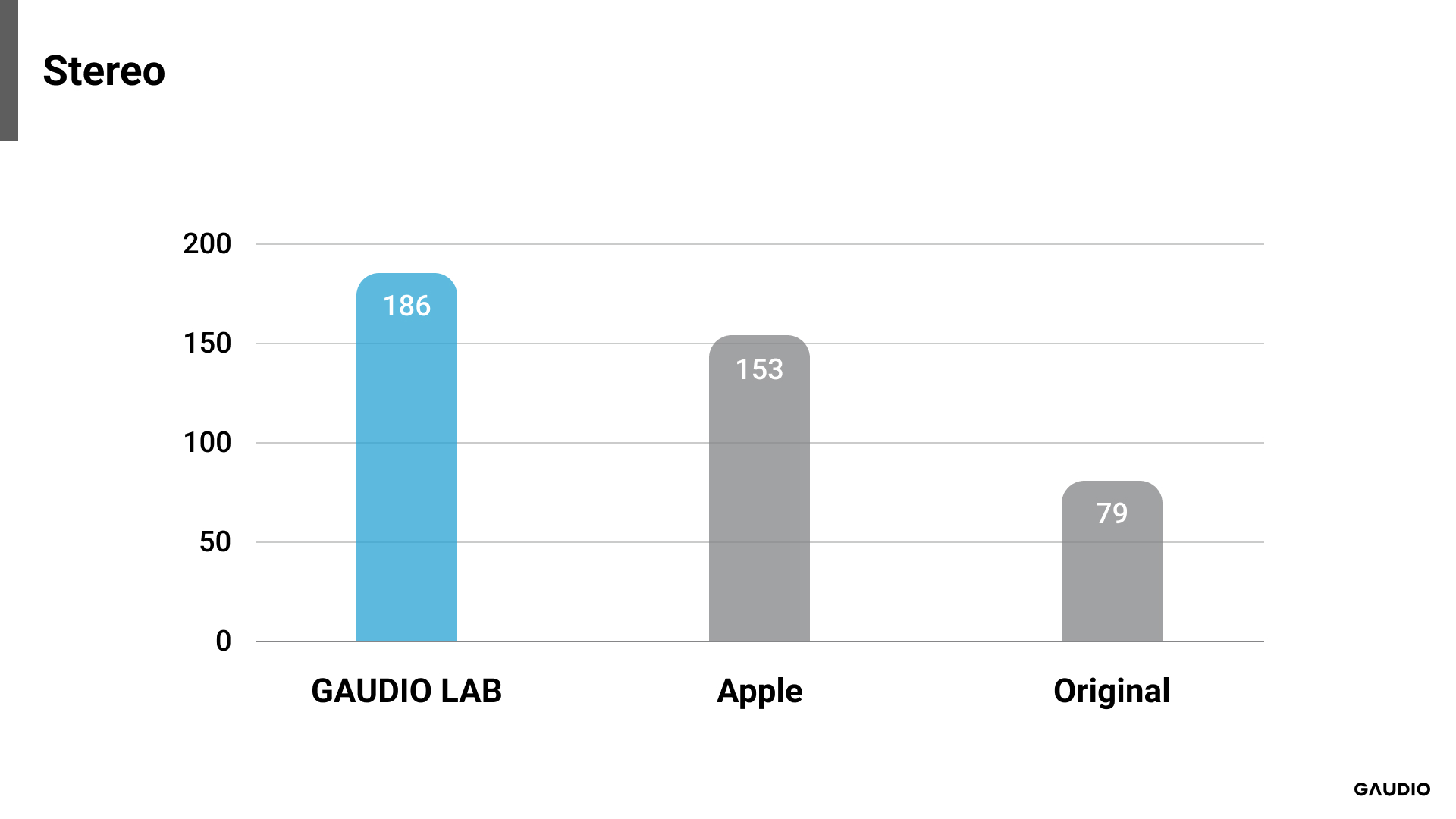
[Image 1: Result from Stereo Sample]
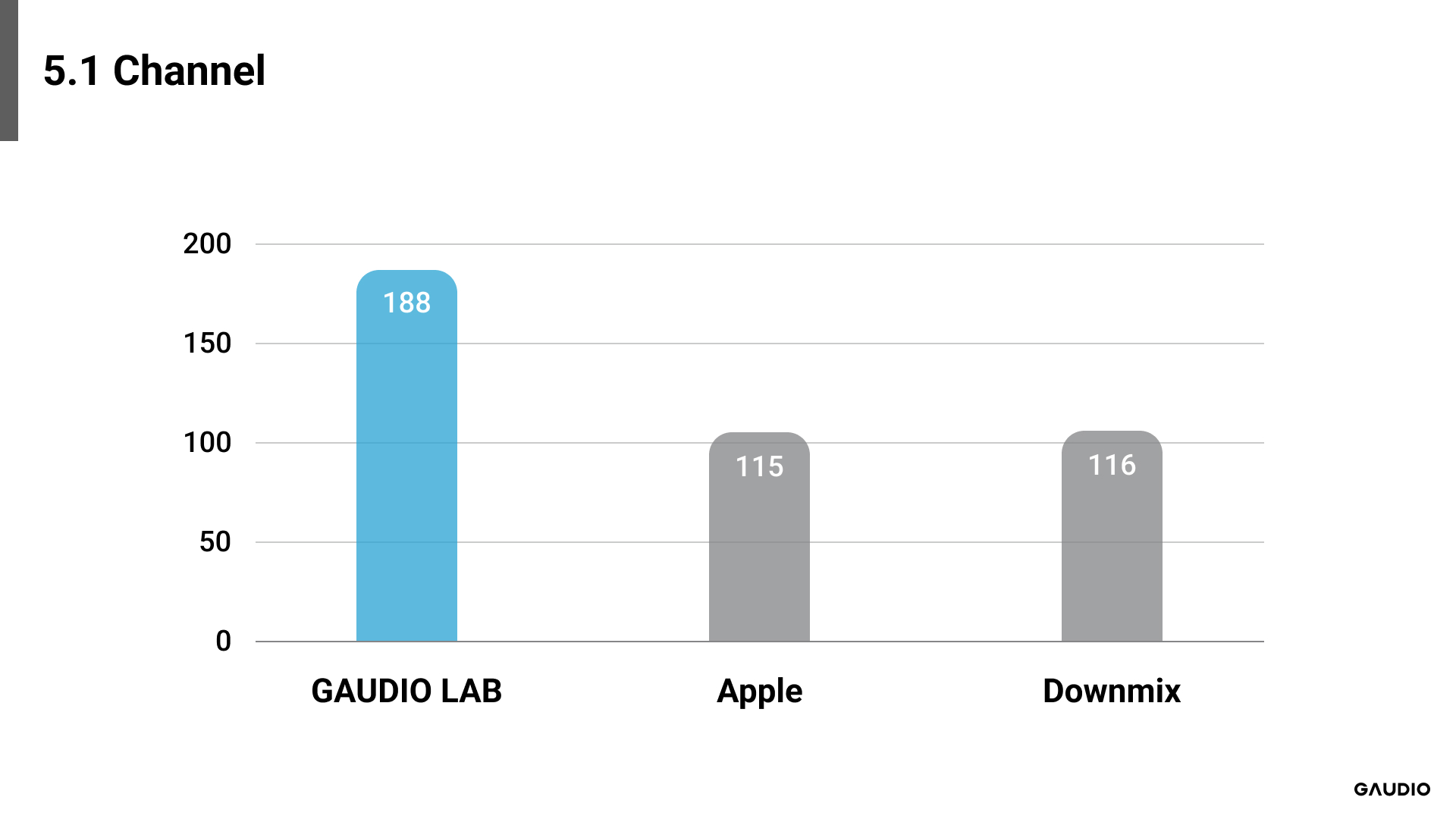 [Image 2: Result from 5.1 Channel Sample]
[Image 2: Result from 5.1 Channel Sample]
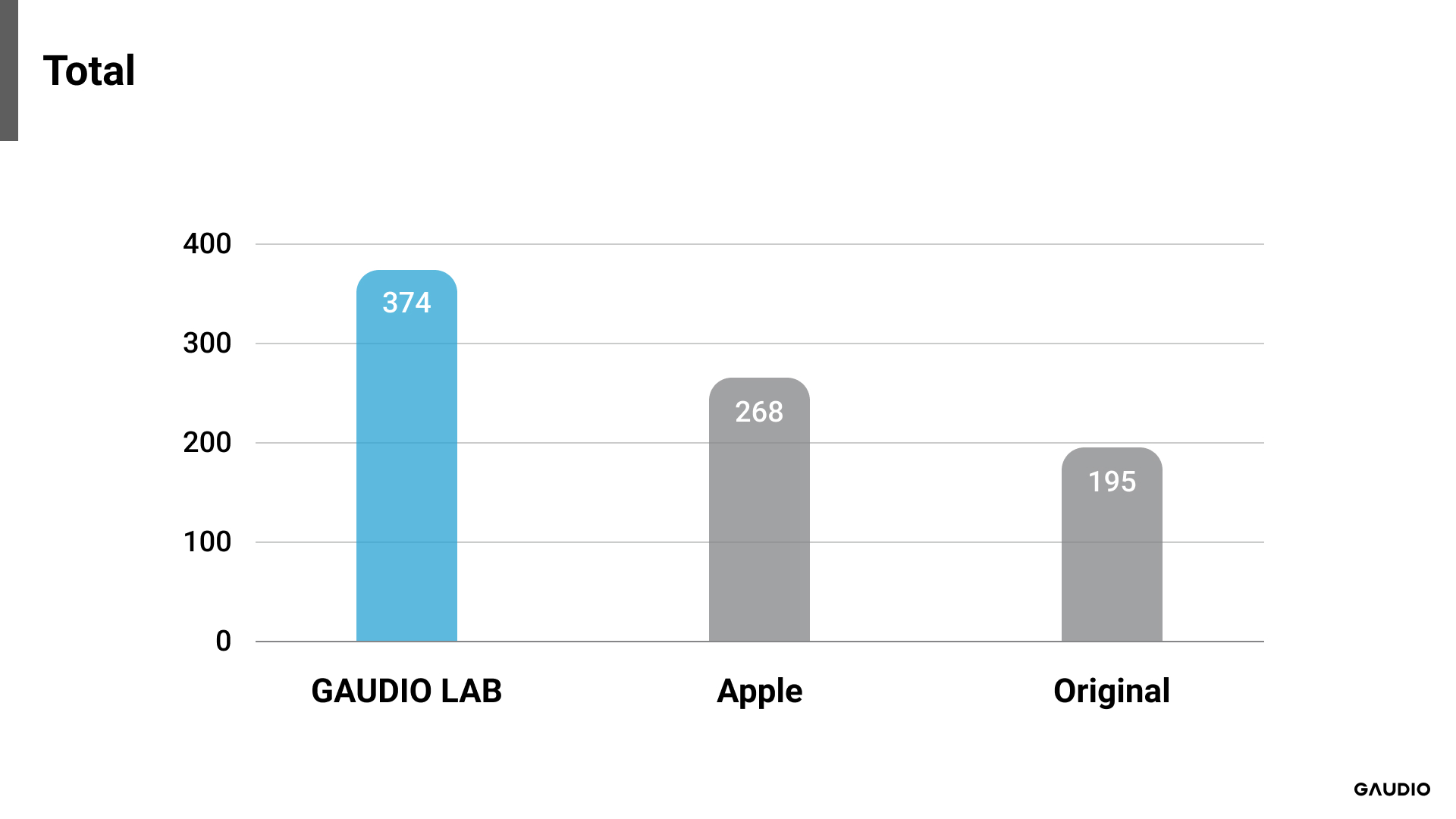
[Image 3: Total Result]
Each evaluation target, for both stereo and 5.1 channel formats, could achieve a maximum score of 280 points. If all participants rated one evaluation target as superior across all audio samples, that system would receive a full score of 280 points. Accordingly, GAUDIO’s GSA system achieved a score of 186 points for stereo audio samples and slightly more, 188 points, for multichannel samples. This data suggests that among the evaluated systems, the GSA received higher preference from the participants.
While GAUDIO’s score was promising, it is equally crucial to determine its statistical significance. Given the overall preference for spatially processed signals, we applied basic statistical methods to analyze the results of GSA and ASA. We isolated the trials that compared GSA and ASA and compared the differences in scores by subtracting ASA’s score from GSA’s. If all participants rated the GSA as superior across all audio samples, the average difference would be 1, and -1 if otherwise. Since relying solely on the mean could be insufficient for determining statistical significance, we also calculated the 95% confidence interval. If this confidence interval includes zero, despite a difference in the mean score, we would conclude that there is no statistical difference between the two systems. Therefore, for GSA to be statistically superior, the mean should be greater than zero, and zero should not be included in the confidence interval.
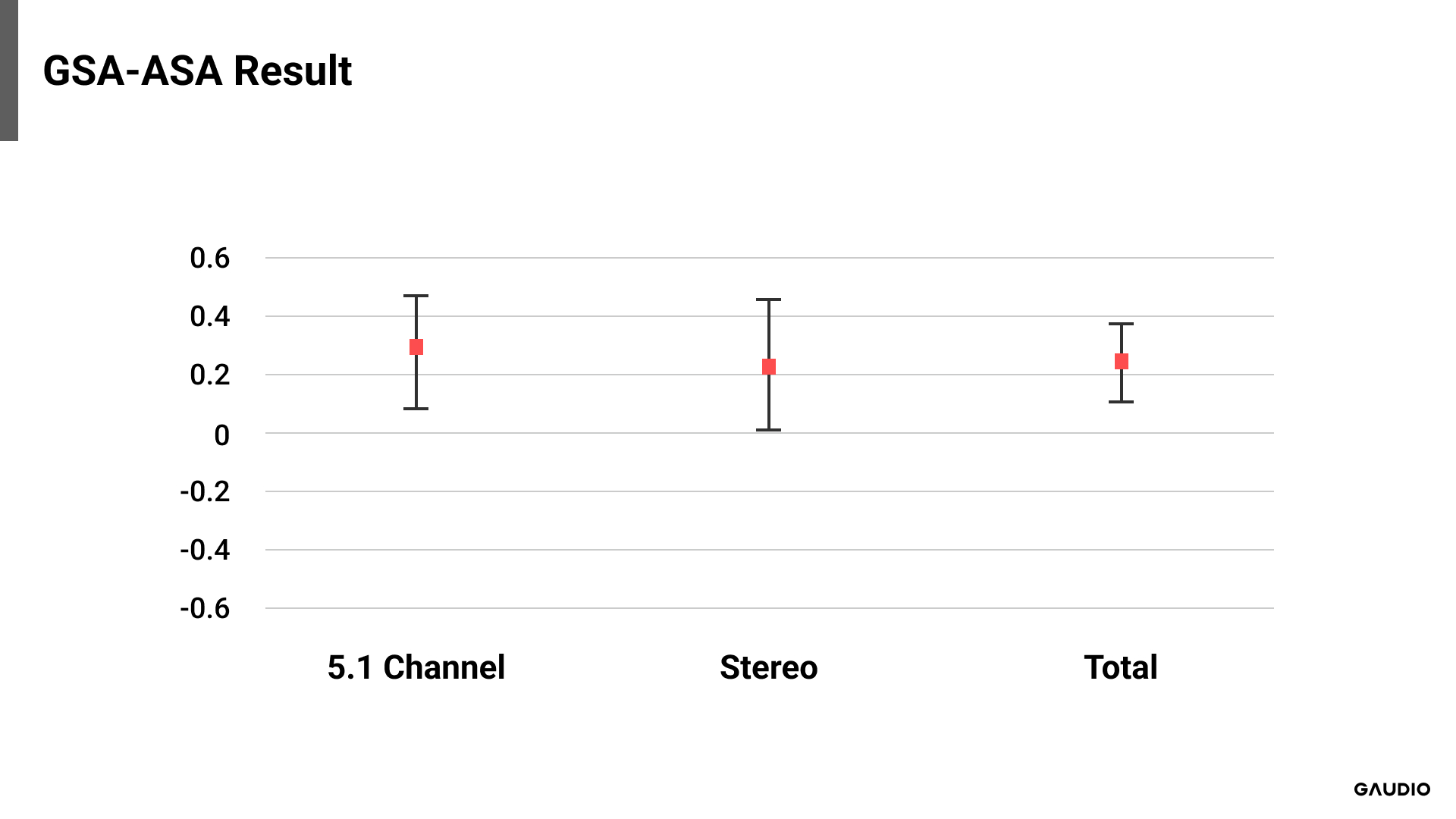
[Image 4: Comparison of GSA-ASA result ]
According to the graph, for both stereo and 5.1 channel signals, the mean is above zero, and the 95% confidence interval does not include zero. This trend persists even when combining both sets of results. Therefore, it’s not merely about GSA earning more points, but at a statistically significant level, the sound rendered by GSA was assessed as superior compared to that rendered by ASA.
But how do the comparative results between GSA and the original, and ASA and the original fare? We used the same method to calculate the mean and the 95% confidence interval, leading to the following outcomes:
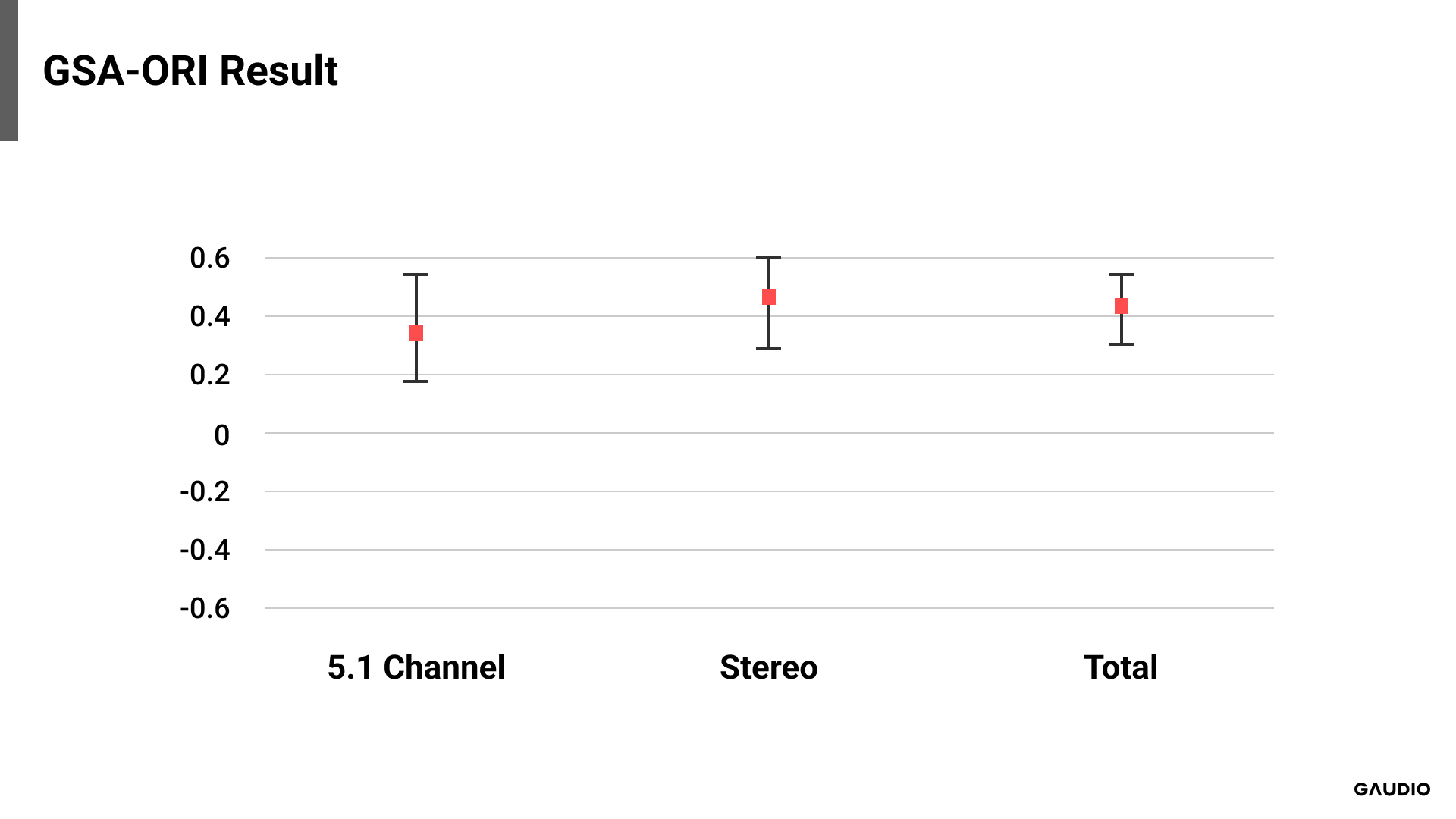 [Image 5: Comparison of GSA - Original]
[Image 5: Comparison of GSA - Original]
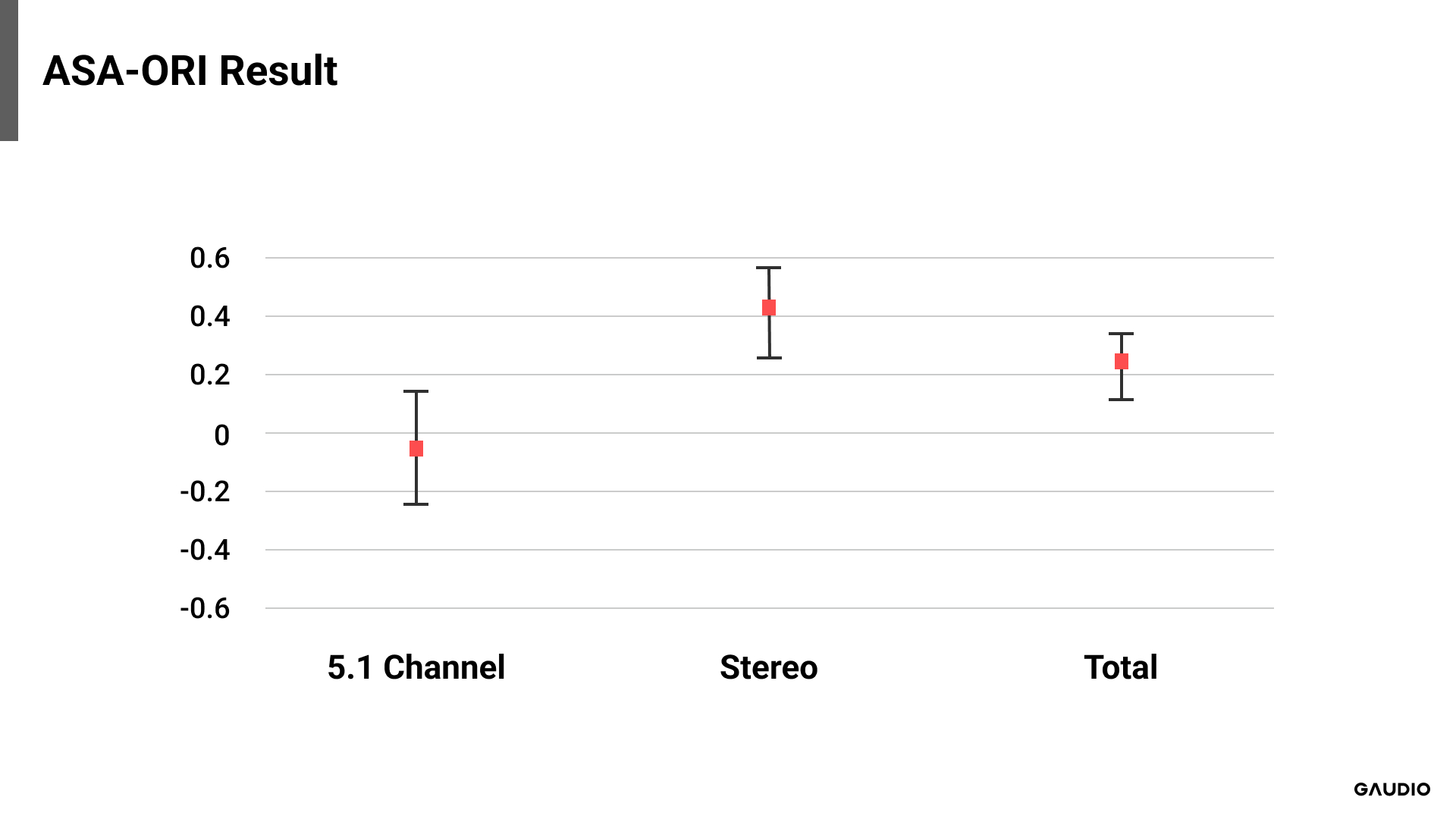
[Image 6: Comparison of ASA - Original]
Upon reviewing the GSA-ORI results, we find that in all cases, the mean is greater than zero, and zero is not included within the confidence interval. Compared to the GSA-ASA results, this confirms that GSA was selected as the preferred sound, statistically and significantly. On the other hand, in the ASA-ORI results, no statistically significant difference was detected between the original and ASA-rendered versions of 5.1 channel audio samples. Although not of great significance, it is noteworthy that the mean score is below zero. Combining all these findings, the sound rendered by GSA was most preferred across all evaluated audio sample formats. This preference for GSA holds true for the 5.1 channel format as well. However, for the downmixed original and ASA-rendered sound, there was no clear preference indicated by the results.
Conclusion
Sound, being both invisible and intangible, often presents a considerable challenge when attempting to clearly communicate its quality. This challenge becomes particularly pertinent when endeavoring to demonstrate the superior sound experience provided by a sophisticated system such as the GSA. Widespread acceptance and application of this technology across markets require us to effectively express the excellence of the system. However, as detailed in the main body of this text, implementing an objective evaluative method for sound is essentially unfeasible. To circumvent this issue, and to objectively represent the performance of GSA for those unable to personally experience it, we undertook this experiment. The aim was to showcase how individual preferences manifest when their experiences with the GSA are compared against their prior experiences with either original sound or Apple’s spatial audio.
Furthermore, we hoped that the GSA achieving positive results in this experiment would boost the confidence and morale of Team Gaudio, who have been tirelessly dedicated to the research, development, and commercialization of this technology. Fortunately, the outcomes were indeed encouraging and brought us a sense of satisfaction. Although the complexities involved in describing the experimental procedures, the results, and the analysis might make this article somewhat intricate, we sincerely hope that this effort, along with our previous work on M2S Latency, will aid in deepening readers’ understanding of the GSA.


Our audio technologies support various devices and platforms.
