Synchronizing lyrics? It's Directly Handled by AI: An Introduction to GTS by the PO
Synchronizing lyrics? It's Directly Handled by AI: An Introduction to GTS by the PO
(Writer: John Jo)
Before we dive into the details of GTS, let me introduce myself.
Greetings! I'm John, the Product Owner (PO) of GTS at Gaudio Lab. I work as the PO of GTS at Gaudio Lab by day, and chase my passion as a jazz vocalist by night. I lead and sing for the New Orleans marching band SoWhat NOLA (shameless plug here).
Do you agree with the phrase, "We listen to music with our eyes 👀"?
What I’m actually referring to, is song lyrics. GTS plays a pivotal role in the 'real-time lyric display' feature seen in today's streaming services. Here, AI autonomously syncs lyrics with their corresponding music.
In this discussion, my goal is to shed light on the inner workings of GTS and explore how this AI product, jointly cultivated by Gaudio Lab and myself, is revolutionizing our world.
The Untold Story Behind 'Real-time Lyric Display'
Currently, most music streaming services offer real-time lyric services.
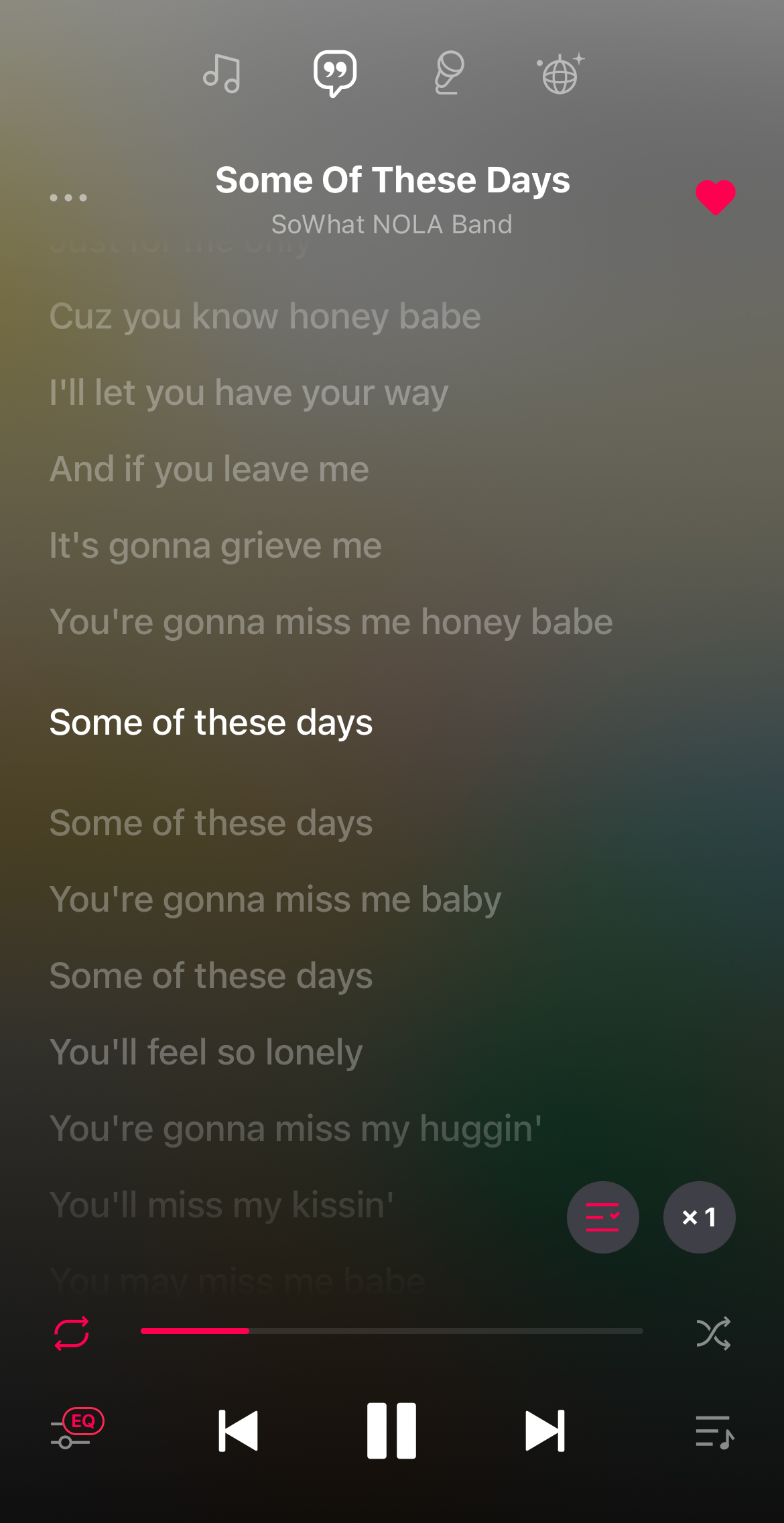
<Here's a snapshot of a real-time lyric service - just like this!>
Until recently, were you aware that the synchronization of lyrics and melody for music streamed online was manually done by individuals?
Unfortunately, the practice of manually synchronizing lyrics comes with its own limitations, some of which may seem familiar:
- It is a time-consuming process. Syncing requires listening to the song in its entirety. If lyrics flow at a rapid pace, as in rap, or if the language isn't your native tongue, the processing time escalates significantly.
- The quality isn't always consistent. As I mentioned earlier, tracks that are harder to sync take longer to process. This makes it near impossible for those handling multiple songs in a day to perfectly process each one.
- The music market is flooded with thousands of songs each day. It's only logical for music streaming services to invest more in labor to ensure proper lyric syncing. Factor in management costs, and it quickly becomes a daunting task.
- It concerns artists as well. I personally experienced difficulties with lyric syncing during my album release. When I released my debut album two years ago, Spotify, an international streaming service, didn't provide real-time lyric services. As a result, I had to painstakingly use a manual sync service. In contrast, I recall the sense of satisfaction I felt with the smooth syncing on local streaming services that had incorporated GTS.
Let's dive deeper into the revolutionary AI solution known as GTS that resolves all these issues at once.
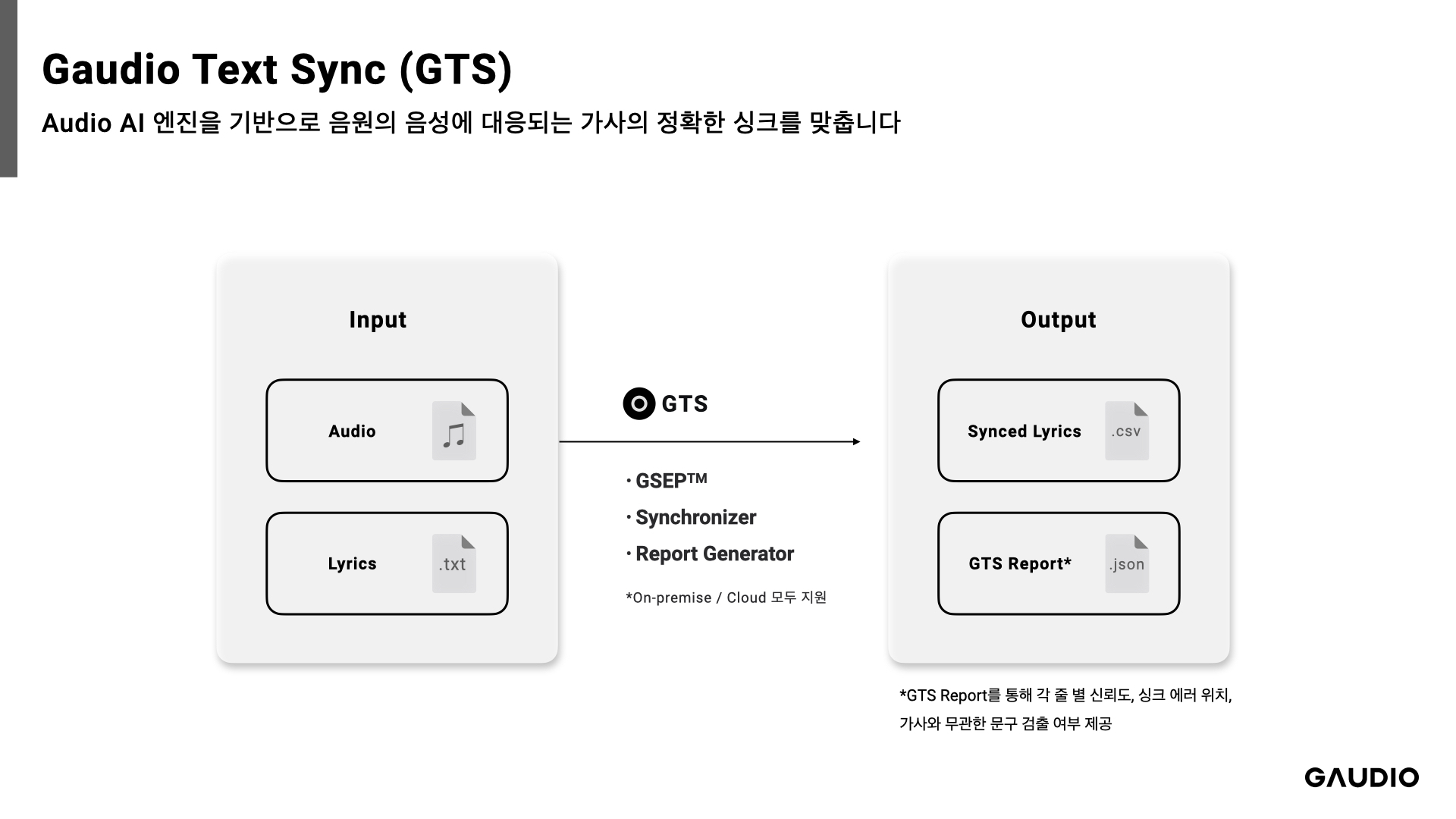
[GTS Concept Diagram]
GTS, short for Gaudio Text Sync, is a tool that [utilizes AI to automatically synchronize lyrics with the audio of a song]. For instance, given an mp3 file of BTS's new song "Take Two," and a txt file with the lyrics, GTS automatically generates a timeline for the lyrics.
If you're curious about how GTS can cut down time and cost, here are your answers:
- GTS only takes about 5 seconds to process a single song and it covers a wide range of languages, including English, Korean, Chinese, and Japanese. Regardless of the song being processed, GTS creates accurate and considerably faster timelines than human capabilities allow. Even high-speed tracks from artists like Eminem pose no problem. For streaming services facing similar challenges, adopting GTS could be a game-changing decision (that will also positively impact your business!)
- GTS not only provides synchronization results, but also offers a detailed 'Sync Result Report' for each song. This report specifies the accuracy of the synchronization and checks if any lines of lyrics have been improperly synced. Users can use this report to effortlessly review and correct any discrepancies in the lyrics or synchronization. (And it could even get you off work sooner!)
- Today, most Korean music streaming services provide real-time lyrics created through GTS to their customers. Foreign streaming services have started to take notice, and we're continually holding intensive meetings with them. We're setting our sights on international expansion. Full speed ahead!
- The surprises don't end here. GTS, which started with creating timelines for each line of lyrics, is now capable of generating timelines down to each word. The R&D team is currently working on advancing the technology to create timelines on a per-character basis, just like you'd see in a karaoke session.
As the saying goes, seeing is believing, so here's a comparison:
Let's take a look at the lyric syncing capabilities of Company G, a leading Korean music streaming platform, and NAVER VIBE. I've selected a track titled "Still a Friend of Mine" by one of my favorite bands, Incognito.
First, let's take a look at Company G's real-time lyrics. You'll notice that the synchronization is off by almost a complete line.
Many of you might have encountered this frustrating and inconvenient situation. It's difficult to navigate to a specific part of a song just by clicking the corresponding lyrics.
Now, let's take a look at VIBE, which has incorporated GTS technology.
With accurate synchronization, the music-listening experience is greatly enhanced. (Plus, VIBE has an exclusive feature allowing you to see native-level translated lyrics!)
GTS is revolutionizing the world in numerous ways.
E.UN Education: Facilitating the enjoyment of music for those with hearing impairments.
It's instrumental in music education services for those with hearing impairments. Through GTS, these individuals can experience music via vibrations corresponding to each syllable. GTS is actively being utilized by E.UN Education in Korea, who are gearing up for the launch of such an application. By determining the beginning and end points of each phrase in a song, GTS assists hearing-impaired individuals in discerning each line of the lyrics. This innovative use of AI technology is a true embodiment of Gaudio Lab's mission to leverage AI for the betterment of society.

[Picture taken during a meeting with E.UN Education]
CONSALAD: Indie musicians can now effortlessly generate lyric videos!
At CONSALAD, lyric videos are created (refer to picture below) and distributed to promote indie artists' new songs.
Here, GTS is utilized to synchronize the lyrics in these videos, illustrating how Gaudio Lab's technology assists indie musicians in their promotional efforts.
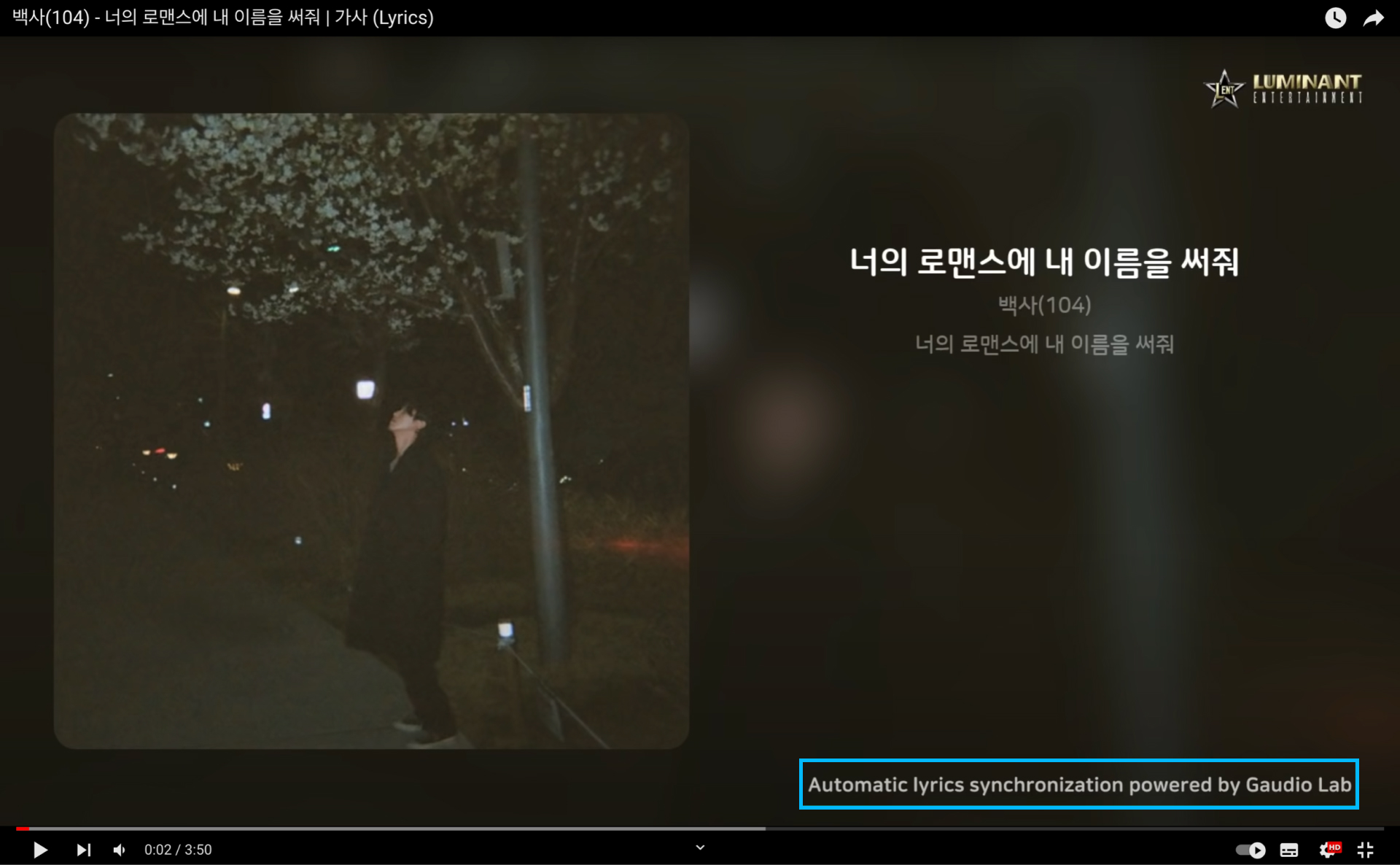
These cases are testament to Gaudio Lab's dedication to 'delivering exceptional auditory experiences through innovative technology'.
However, the journey of exploring GTS's potential doesn't stop here. The applications of GTS are endless…
- GTS can be applied wherever there is a need for synchronization between text and sound.
- In OTT or videos, where synchronization between closed captions and audio is required.
- In audiobooks, where synchronization between audio and text is essential.
- In language learning, where synchronization between audio and text is crucial.
- Furthermore, GTS can be incorporated into a much broader array of applications than you might think, and I'm always open to further exploration and discussion.
In conclusion,
The first project I undertook when I joined Gaudio Lab was the commercialization of GTS. Today, GTS is widely used in most of Korea's music streaming services, and it's gratifying to see how it enhances the music experience for many users.
My next goal is to speed up the implementation of GTS in a multitude of music/OTT streaming services around the world.
If you are interested in enhancing the auditory experiences of users worldwide, don't hesitate to reach out to us at Gaudio Lab!

Our audio technologies support various devices and platforms.
