Integrating the Audio AI SDK into WebRTC (2): Methodology for Building a Testing Environment
Integrating the Audio AI SDK into WebRTC (2): Methodology for Building a Testing Environment for Effective Integration Development
(Writer: Jack Noh)
As outlined in the previous post (Integrating Audio AI SDK with WebRTC (1): A Look Inside WebRTC's Audio Pipeline), WebRTC is a substantial multimedia technology, encompassing audio, video, and data transmission, among other aspects. Even considering the audio segment alone, it encompasses various modules (APM, ACM, ADM, …). It's a testament to the high applicability of this technology. In this upcoming post, I plan to share the methodology behind creating a 'robust testing environment' — a critically significant step when incorporating an Audio AI SDK into WebRTC.
WebRTC Audio Processing Module
Among the audio modules in WebRTC, which one is most suited for integrating a noise suppression filter? You may have already inferred from previous posts, the module most compatible for such integration (indeed, specifically designed for this purpose) is the Audio Processing Module (APM). Primarily, the APM is a collection of signal-processing based audio filters constructed with the aim of enhancing call quality.
The Audio Processing Module chiefly functions as an essential module imparting effects on audio at the client-side. This module is designed with the purpose of assembling filters that elevate the quality of audio signals, making them suitable for calls. These filters, also known as sub-modules within the APM, carry out various functions.
Here's a brief introduction of some prominent sub-modules in WebRTC:
- High Pass Filter (HPF): This filter operates by removing low-frequency signals to isolate high-frequency ones, such as voice.
- Automatic Gain Controller (AGC): This filter maintains a uniform level by automatically adjusting the amplitude of the audio signal.
- Acoustic Echo Cancellation (AEC): This filter eradicates echo by preventing signals from the speaker (far-end) from reentering the microphone.
- Noise Suppression (NS): A signal-processing-based filter that eradicates ambient noise.
These sub-modules are strategically used in both Near-end Streams (where microphone input signals are transmitted to the other party) and Far-end Streams (where audio data received from the other party are outputted to the speaker). To illustrate this, consider the example of a video conference scenario.
Initially, the audio signal inputted into the microphone is processed through the High Pass Filter (HPF) to eradicate low-frequency noise. Then, to prevent discomfort from abrupt loud sounds, the signal passes through the Automatic Gain Controller (AGC) which automatically adjusts the signal's amplitude. Following this, the Acoustic Echo Cancellation (AEC) comes into play, preventing echo by stopping signals from the speaker from reentering the microphone. Finally, the Noise Suppressor (NS) eliminates any remaining ambient noise.
Visual representations often simplify the explanation process compared to textual descriptions. The function ProcessStream() depicted in the diagram below signifies the processing of the signal stream captured from the microphone, a pathway often referred to as the forward direction. Concurrently, ProcessReverseStream() exists to handle the processing of the reverse stream, which aims to render audio data received from a remote peer via the speaker. Each of these processes can be understood as an effect-processing step within the Near-end Stream and Far-end Stream of the APM.
Let's revisit the aforementioned process flow via the following diagram:
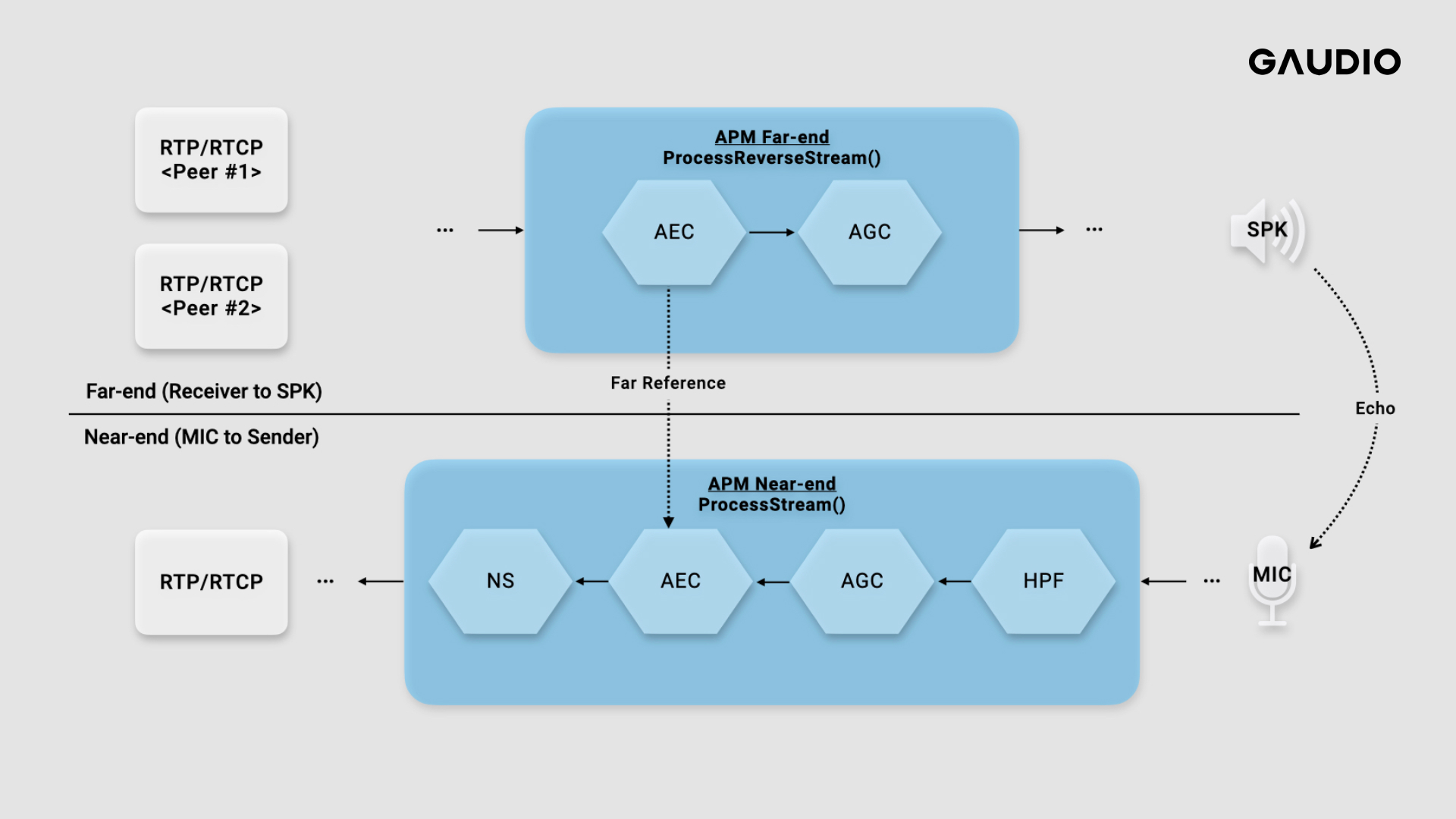
(WebRTC Branch: branch-heads/5736)
It's crucial to note that the two stream processing stages are not independent. This is because, in order to mitigate the echo—a situation where the voice of the other party enters the microphone again—the signal needs to be analyzed within the ProcessReverseStream() before being passed onto the ProcessStream() for echo cancellation. (This is the role of AEC as discussed earlier!)
With an understanding that the structure of WebRTC's APM is as described, my intention was to integrate it with Gaudio Lab’s superior audio separation technology, GSEP-LD. At first glance, it seems logical to replace NS with GSEP-LD, but is this the optimal strategy?
From a signal processing perspective, this might seem plausible. However, as the SDK we intend to integrate is AI-based, it's not possible to conclusively determine this. Positioning it before AEC might enhance the output, or conversely, placing it at the very end might yield superior results.
In response to the question 'Would the optimal integration location coincide with the location of the existing noise removal filter?' numerous additional queries arise:
‘Will there be any side-effects with other Submodules?’
‘What about simultaneously using NS and GSEP-LD?’
‘Is it necessary to utilize the HPF filter to eliminate low-frequency noise?’
‘How would the efficacy of GSEP-LD alter depending on the operation of AEC?’
Upon analyzing WebRTC's APM, it became clear that several elements need to be carefully evaluated during testing. Now, let's delve into strategies for robust testing of these scenarios.
Note that the integration of another SDK as a Submodule into WebRTC is not particularly challenging. This article primarily discusses the establishment of a test environment for the WebRTC Audio pipeline and will not extensively cover this topic, but here is a brief overview:
WebRTC's APM is scripted in C++ language. Initially, a Wrapper Class is devised to manage instances and states, mirroring the functionality of other Submodules within the APM. Subsequently, the Wrapper Class that you wish to integrate is embedded into the actual APM Class, and is managed in a similar fashion to other Submodules.
Leveraging APM CLI for Efficient Integration
Building upon our comprehension of the APM module, we now aim to establish a rigorous testing environment to derive results from GSEP-LD. For this, creating a Command Line Interface (CLI) capable of running the APM independently proves effective for obtaining file output results (Indeed, we need to actually hear the output!)
We have identified two methods for harnessing the APM CLI for efficient integration:
1) Method one involves using WebRTC's open-source resources directly.
2) Method two makes use of an open-source project that exclusively features the WebRTC APM.
1) Utilizing WebRTC's Open Source Directly
WebRTC's open-source resources can be directly accessed from the following link. The WebRTC project offers comprehensive guides on build procedures for each platform. Upon downloading the source code, installing the necessary software according to the guide, and ensuring a successful build, you are then equipped to use the APM CLI!
By checking the build path, you will be able to locate audioproc_f , a file mode testing tool for APM. With audioproc_f , you can feed a WAV file into the APM and obtain an output that has been processed through the audio filtering effects of the APM. To verify the APM output results using default settings, execute the following command:
$ ./audioproc_f -i INPUT.wav --all_default -o OUTPUT.wav
The testing environment can also be customized. For the next step, we will set the stream delay between the Near-end and Far-end to 30ms and activate the Noise Suppressor. Here, 'stream delay' refers to latency introduced by hardware and system constraints. Notably, to improve the performance of AEC, accurately specifying the stream delay between Near-end and Far-end is crucial, making it an important parameter to be cautious of during testing.
./audioproc_f -i INPUT.wav --use_stream_delay 1 --stream_delay 30 --ns 1 -o OUTPUT.wav
2) Leveraging an Open Source Project Solely Featuring WebRTC APM
The first method indeed offers a substantial level of testing. By modifying the source code of audioproc_f , a robust test environment can also be established. However, within the WebRTC project, there exists a range of additional, nonessential multimedia source codes (such as those pertaining to video, data network source codes, and other modules like ADM, ACM for audio only), thereby presenting a disadvantage due to their redundant presence. Consequently, we contemplated the possibility of devising a leaner test environment focusing exclusively on the APM, the essential component. In the course of this consideration, we stumbled upon a valuable open source project which enables us to isolate and structure tests solely for the WebRTC's APM module (Special thanks to David Seo for suggesting the idea!). This constitutes our second method.
Here is the link to the open source project employed in the second method. This particular project provides the opportunity to separate the APM of WebRTC and assemble it using the Meson build system.
A brief interjection on Meson: Meson represents a forward-thinking C++ build system, capable of constructing codes more swiftly compared to other build systems such as CMake, primarily due to its user-friendly syntax. Furthermore, it offers straightforward handling of test cases and management of test architectures. To compose a unit test in Meson, you first generate a test execution file encompassing the test code, and subsequently, inscribe the test code in said file. Afterwards, you define the test with the test() function and instruct Meson to carry it out. For instance, you could draft a code as follows:
test('test_name', executable('test_executable', 'test_source.cpp'), timeout: 10)
This code specifies a test named test_name . It conducts the test by operating test_source.cpp, a test execution file constructed from the test_executable file. The timeout parameter assigns the duration for the test to be carried out, expressed in seconds. If the test fails to complete within the stipulated time, it is deemed unsuccessful. It's noteworthy that the test execution file is capable of receiving arguments, thereby allowing for the application of different values to accommodate various scenarios.
Having covered the simplified process of crafting test codes with the Meson build system, the subsequent step involves orchestrating the tests for integrating GSEP-LD. The subsequent image offers a representation of the test design we assembled (albeit it being more abridged than the actual test we conducted).
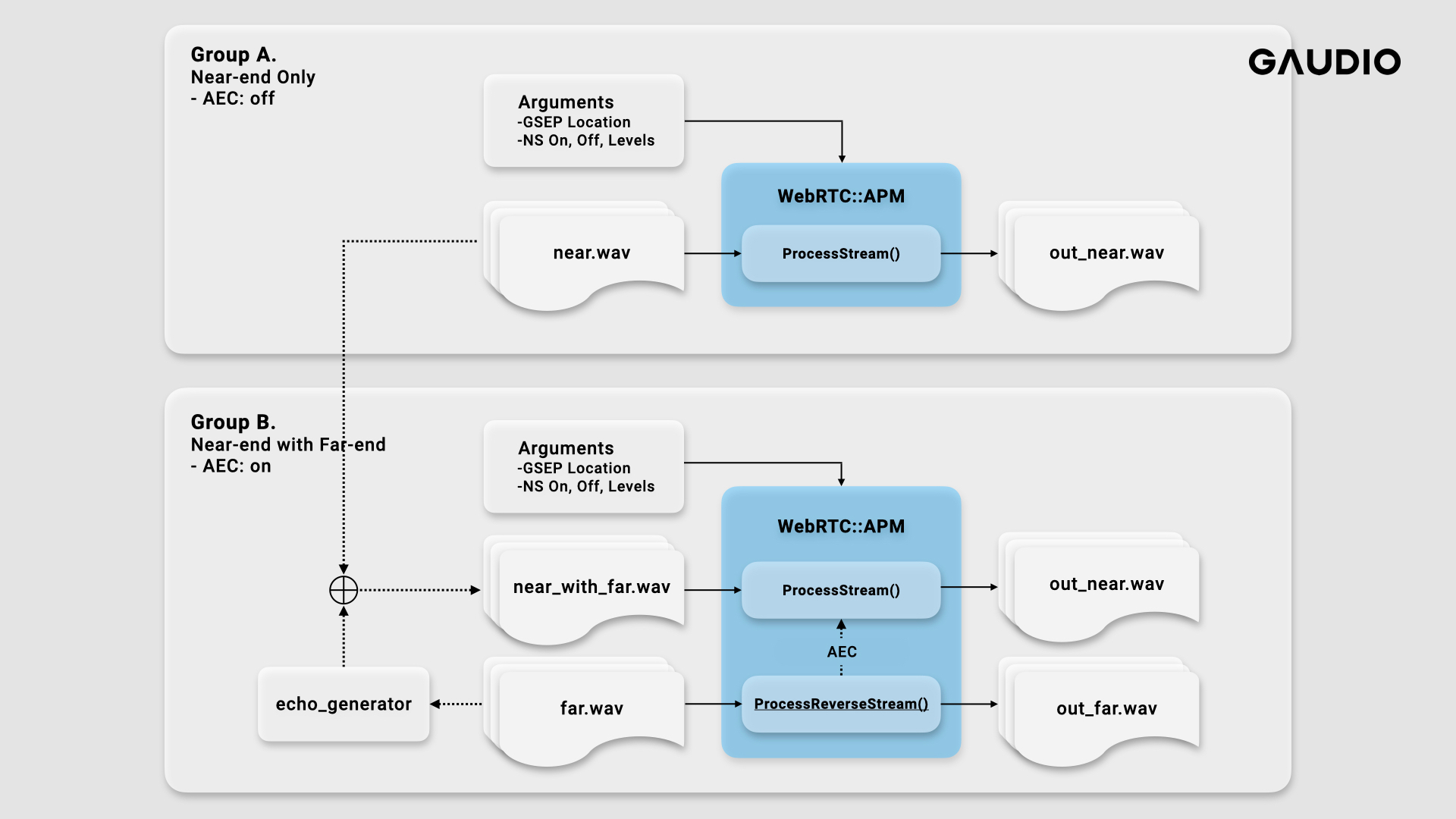
First, we partitioned our tests into two primary categories. As you may know, there are two types of streams in WebRTC: Near-end and Far-end streams. We designated these as Group A and Group B, respectively.
The principal distinction between the two groups lies in the operation of the Acoustic Echo Canceller (AEC), responsible for echo removal. (When only the Near-end stream is active, the AEC is turned off, whereas it is enabled when both the Near-end and Far-end streams are utilized.)
Each group also has a unique configuration for the input files. In Group A, the signal consisting of speech through a microphone with added noise suffices as the input. However, Group B requires a simulation that mimics a scenario where the output signal from a speaker (i.e., the signal produced by the other party) re-enters as an echo. The echo_generator serves this purpose. The input signal for Group B is formed by summing the echo originating from the echo_generator with the signal transmitted through the microphone.
Subsequently, we controlled the integration point and operation of GSEP-LD. The integration was managed at the forefront of the processing (Pre-processing), at the existing noise removal filter's location, and finally at the Post-processing stage.
It is essential also to examine the potential side effects with other submodules, isn't it? Let's explore the side effects concerning the Noise Suppressor (NS). To validate the side effect with NS, we toggled its status and set the parameter controlling the degree of noise reduction. It's worth mentioning that the noise reduction parameter in NS can be set anywhere from Low ~ VeryHigh. However, employing an excessively high value may lead to significant sound distortion.
Finally, we categorized the noise types present in the input file. We performed tests for a variety of noise types, including noise typically found in a café, car noise, and the sound of rain. Despite this degree of detail leading to a substantial number of test branches (owing to the multiplication of each independent branch), the test functionality of the Meson build system allows for easy generation using just a few for-loops. Below is a pseudo-code depiction of the Meson build file.

The test code is then complete. Using Meson commands to execute the prepared test code enables us to cover all designated test branches and obtain respective output results.
The test went well and creating the output
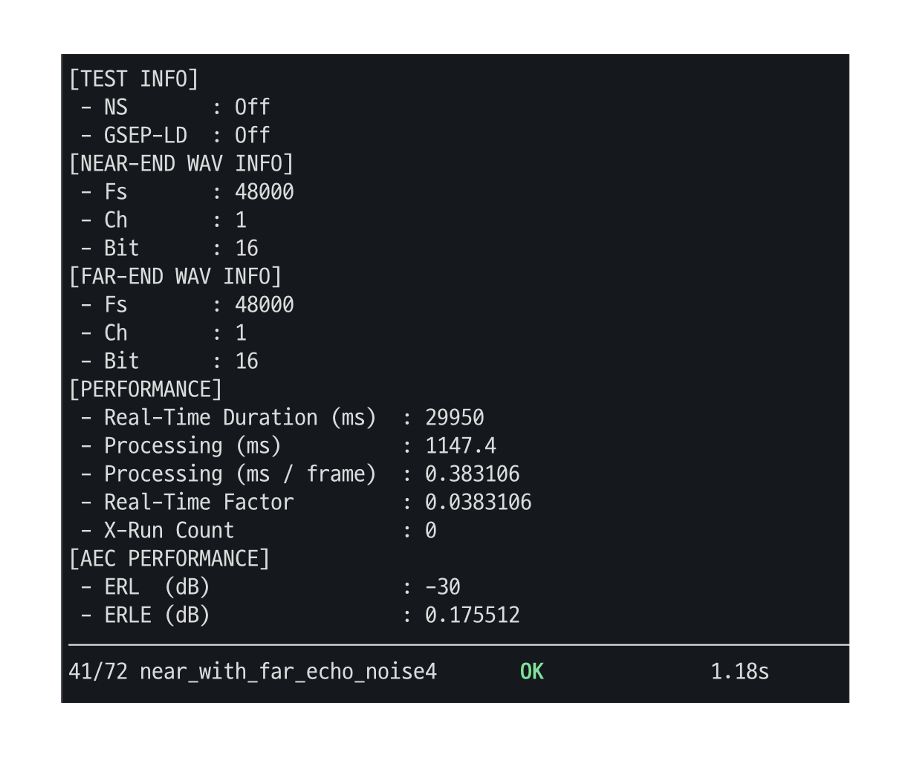
Check metrics to be ensured the test went well
Conclusion
In a project like WebRTC, which encompasses numerous technologies, integrating a third-party technology presents a host of considerations. One must understand the overall flow for selecting an integration point and anticipate the integration across a multitude of environments. These environments involve the location of integration, the operating environment, and the potential side effects with pre-existing technologies. The details discussed above take into account relatively straightforward cases. Nevertheless, we are still presented with: Noise types (5 types) x AEC On/Off (2 types) x NS settings (5 types) x GSEP On/Off (2 types) = 100 scenarios!
These 100 scenarios require consideration. However, in practice, the need to test an even wider variety of noise types, consider additional submodules beyond NS, and account for platform-specific differences (Windows, MacOS, etc.) results in an exponential increase in the number of test cases. Furthermore, should the GSEP positioning need to be controlled across a broader range of locations for testing purposes, it becomes rather confusing.
In this article, we have shared our experience of effectively managing complex scenarios, utilizing a more streamlined Command Line Interface (CLI) environment for testing. Our learnings have demonstrated that by harnessing the capabilities of the open-source projects that isolate WebRTC's Audio Processing Module (APM) and employing the testing feature of the Meson build system, a relatively straightforward environment construction is feasible. If you wish to integrate specific filters into WebRTC in the future, we hope this article provides some insights and assistance. Thank you for taking the time to read this article.
+) For those eager to integrate Gaudio Lab’s unique audio SDK into WebRTC and develop a service, you are always most welcome!
+) Thanks to David Seo for letting me know about WebRTC's audio popeline, and for the idea of using an open source that stands alone as a WebRTC APM!

Our audio technologies support various devices and platforms.
