How Can We Estimate RIR in Environments with Multiple Sound Sources?
How Can We Predict RIR in Environments with Multiple Sound Sources?
Introduction
Greetings! I’m Monica from Gaudio Lab, a pioneering hub for audio and AI research.
The recent introduction of Apple's Vision Pro has sparked renewed enthusiasm for Spatial technology. This development extends into the realm of audio, suggesting that by understanding a user’s spatial surroundings, a deeper audio experience can be curated. Coincidentally, Gaudio Lab embarked on related research last year, and I am excited to share our insights.

Understanding Room Impulse Response (RIR) : A Key Concept to Remember
If you’ve ever thought, “I want to make a sound seem as if it’s coming from a specific space!”, all you need to know is Room Impulse Response (RIR).
RIR measures how an impulse signal, like the gunshot from a man in Figure 1, reverberates within a given space. Any sound, when convoluted with the RIR of a specific space, can be made to sound as if it originates from that space. Thus, we can describe RIR as "data that contains invaluable information about that space".
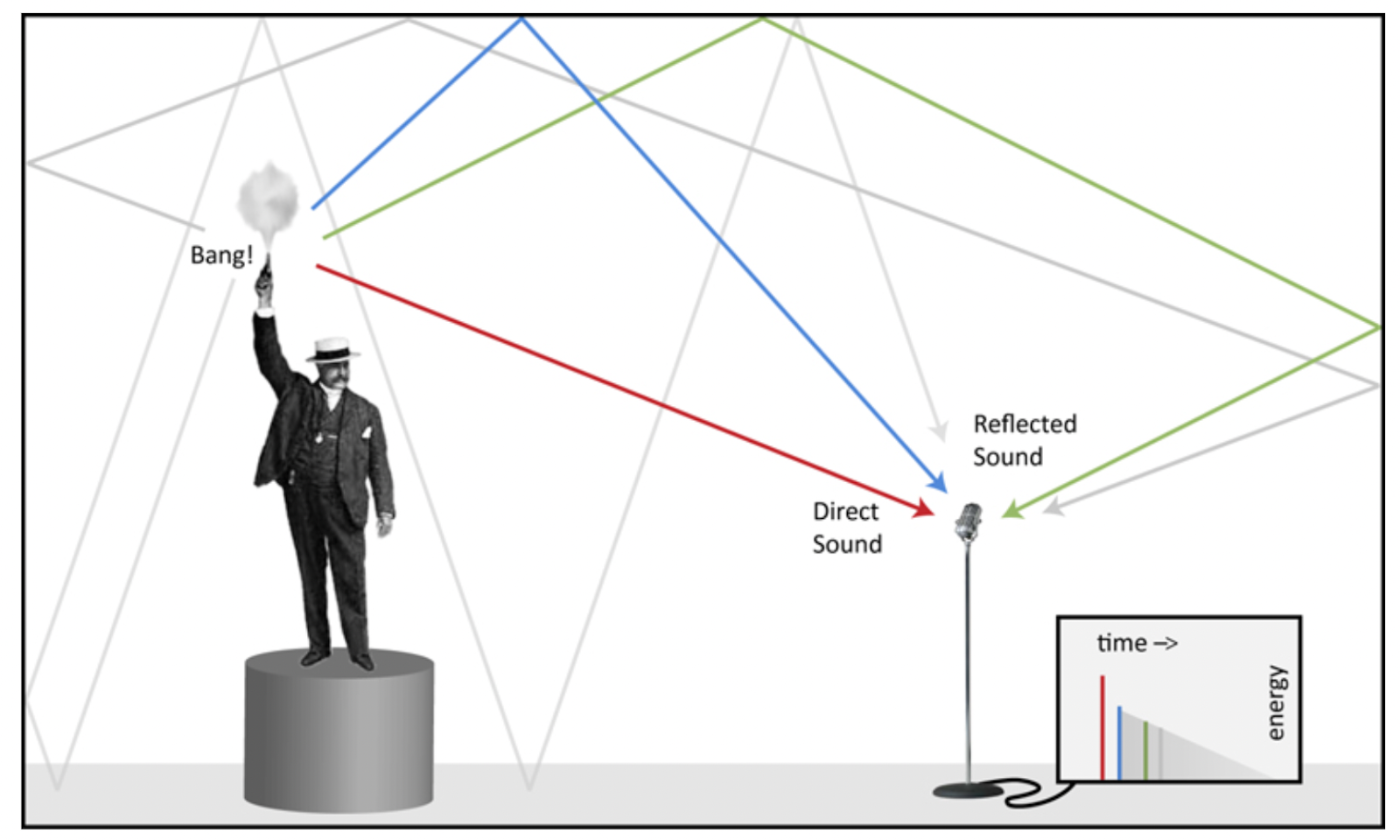
Figure 1 – Source: https://www.prosoundweb.com/what-is-an-impulse-response/
So, how can we estimate RIR?
The most accurate method to obtain RIR data involves direct measurements with a microphone in the targeted area. However, this method, while precise, is often cumbersome, requiring both specialized equipment and considerable time. Moreover, physical barriers might restrict access to certain spaces. Fortunately, the evolution of machine learning presents alternative RIR prediction techniques. For instance, one such study aims to predict the RIR of a space using only a sound recording (e.g., a human voice) from that particular area.
Can TWS Record Surrounding Sounds to Predict RIR in Real-Time?
For a genuinely immersive augmented reality (AR) experience, it’s essential that virtual auditory cues seamlessly blend with the user’s physical environment. This demands an accurate understanding of the user’s immediate surroundings. Our research dives into the potential of using True Wireless Stereo (TWS) to record ambient sounds, which are then analyzed through machine learning.
When predicting real-time auditory experiences within a user’s environment, it’s crucial to consider that multiple sound sources, such as various individuals and objects, will contribute to the soundscape. In contrast, much of the previous research has been tailored towards predicting Room Impulse Response (RIR) from audio cues of a solitary entity, or a “single source.”
While on the surface, RIR prediction for single and multiple sources might appear analogous, they necessitate distinct approaches and considerations. This divergence is due to the inherent variability in RIR measurements, even within the same space, based on the exact positioning and orientation of individual sound sources. While commonalities exist due to the shared environment, specific nuances in measurements are inevitable.
Let’s only predict the RIR in front of us!
Predicting the Room Impulse Response (RIR) in environments with multiple sound sources can be challenging. At Gaudio Lab, we tailored our approach to align with anticipated scenarios for our upcoming products. Recognizing the needs of True Wireless Stereo (TWS) users, we determined that predicting the RIR from sources directly in front should be prioritized. As depicted in Figure 2, even when multiple sounds are recorded, our primary objective remains to estimate the RIR originating from a sound source situated 1.5 meters directly in front of the user.
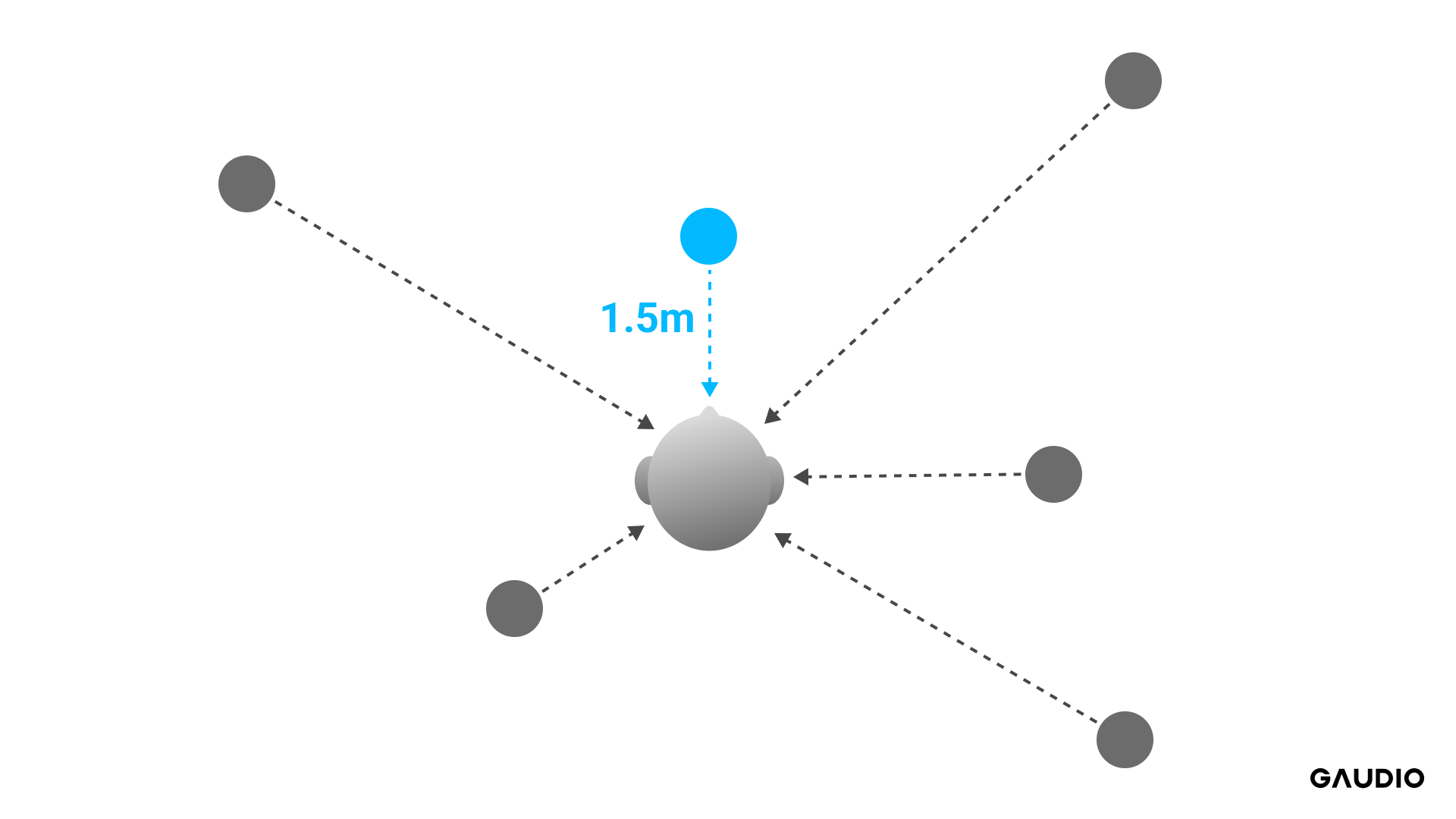
Figure 2 – The user is at the center, surrounded by diverse sound sources being emitted from different positions (grey circles).
Despite the presence of multiple sound sources, our model consistently assumes a virtual sound source (blue circle) located 1.5 meters ahead and aims to predict its RIR.
Our AI model’s architecture takes cues from a relatively recent study. At its essence, the model takes in sound from a designated environment and outputs the associated RIR. Most previous studies primarily used datasets from single-source sound environments (Figure 3, Top). In contrast, our approach incorporates multi-source datasets (Figure 3, Bottom).
We constructed our dataset by convolving select RIRs from Room A with an anechoic speech signal. The model’s output provides a singular monaural RIR, corresponding to the user’s frontal perspective. We crafted a loss function to ensure the model’s output closely matches the true RIR.
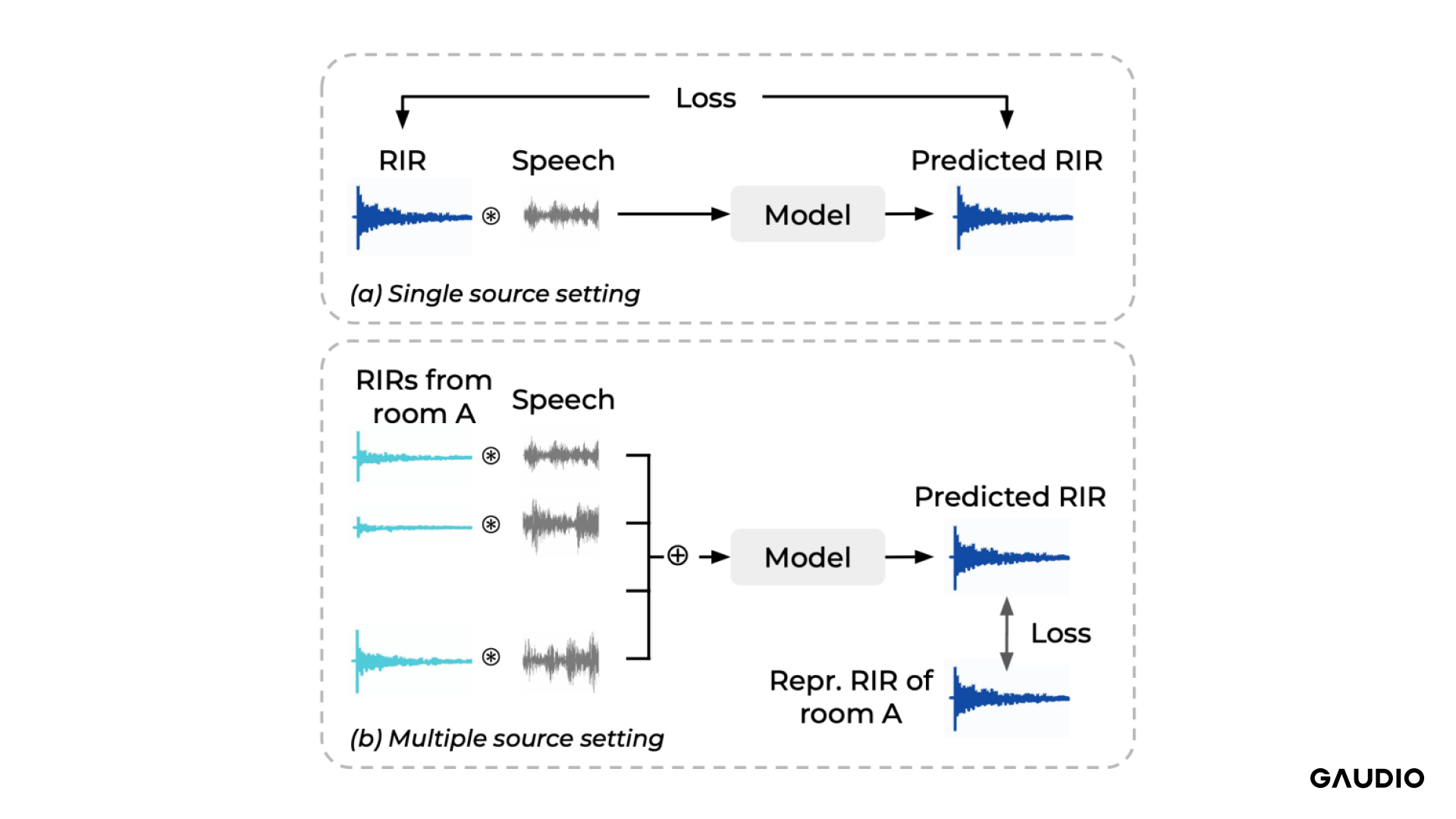
Figure 3 – Traditional studies predominantly utilized single-source environment data for training (top figure),
whereas our method emphasizes datasets from multi-source settings (bottom figure).
The essence of AI system development lies in data collection, a phase in which we invested significant time and effort. While RIR data is plentiful, datasets that capture multiple RIRs within a single environment are scarce. Directly recording from countless rooms was a daunting prospect. To address this, we turned to open-source tools, enabling us to generate and utilize synthetic datasets effectively.
The Outcome?
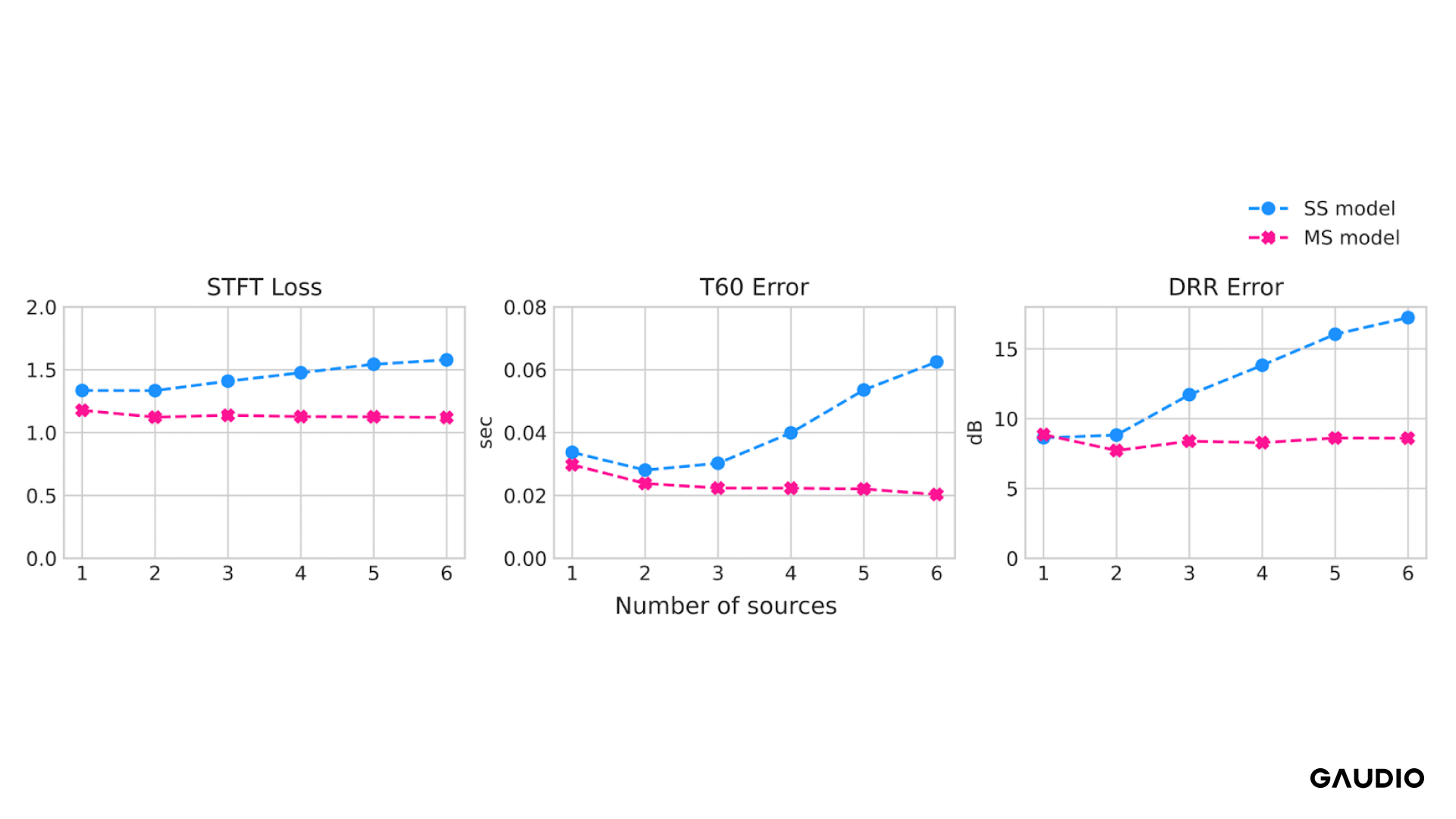
Figure 4 – Comparative analysis between the conventionally studied Single Source model (SS model) and our proposed Multi-Source model (MS model).
An uptick in both Loss and Error values indicates a decrease in performance.
When comparing the traditionally trained model using a single sound source (SS model, illustrated in blue) to our approach, which incorporates multiple sound sources (MS model, depicted in pink), distinct performance variations emerge. As highlighted in Figure 4, the efficiency of the single-source model diminishes as the number of sound sources increases from one to six. In stark contrast, our multi-source model consistently maintains its efficiency in RIR prediction, irrespective of the growing number of sound sources.
In real-world settings, it’s often challenging to determine the exact number of sound sources in a user’s vicinity. Therefore, a model like ours, capable of predicting the RIR of a space regardless of the number of sound sources, promises a more immersive auditory experience.
Curious about this research?
Based on our findings, I developed a system to predict RIRs in real-time from sounds recorded directly in three different office spaces of Gaudio Lab. Each space had its unique characteristics, but the model was able to reliably predict the RIR reflecting that space! During our auditory evaluation with the Gaudio team, the majority remarked, “It truly sounds like it’s coming from this space!” 😆
This research is also scheduled to be presented at the AES International Conference on Spatial and Immersive Audio in August 2023 (NOW!). If you’re interested, please check out the link for more details!


Our audio technologies support various devices and platforms.
