[FALL-E 체험기] MS 나델라 CEO가 감탄한 AI 생성 효과음, 어디까지 진화했을까
들어가며
가우디오랩의 FALL-E는 이미지, 텍스트, 동영상 등 input에 맞게 자동으로 소리를 만들어주는 오디오 생성 AI 기술입니다.
소리는 크게 1) 음성, 2) 음악, 3) 효과음으로 나눌 수 있습니다. FALL-E는 그 중에서도 3) 효과음을 염두에 두고 만들어진 기술이에요.
우리 주변에서는 목소리나 음악을 만들거나 변조하는 AI를 쉽게 찾아볼 수 있는 반면, 그 외의 모든 소리(효과음)를 만드는 AI는 찾아보기 어렵습니다.
키보드 타이핑 소리, 발걸음 소리, 나무에 바람이 스치는 소리..., 우리 주변에 이렇게도 많은 소리가 있는데 말이죠! 이제 그 역할을 FALL-E가 해내려고 합니다.
최근 가우디오랩은 FALL-E를 직접 사용해볼 수 있는 데모 페이지를 오픈했습니다. 누구나 간단히 프롬프트를 입력하면 원하는 소리를 만들어낼 수 있습니다.
아래 화면처럼 말이죠.
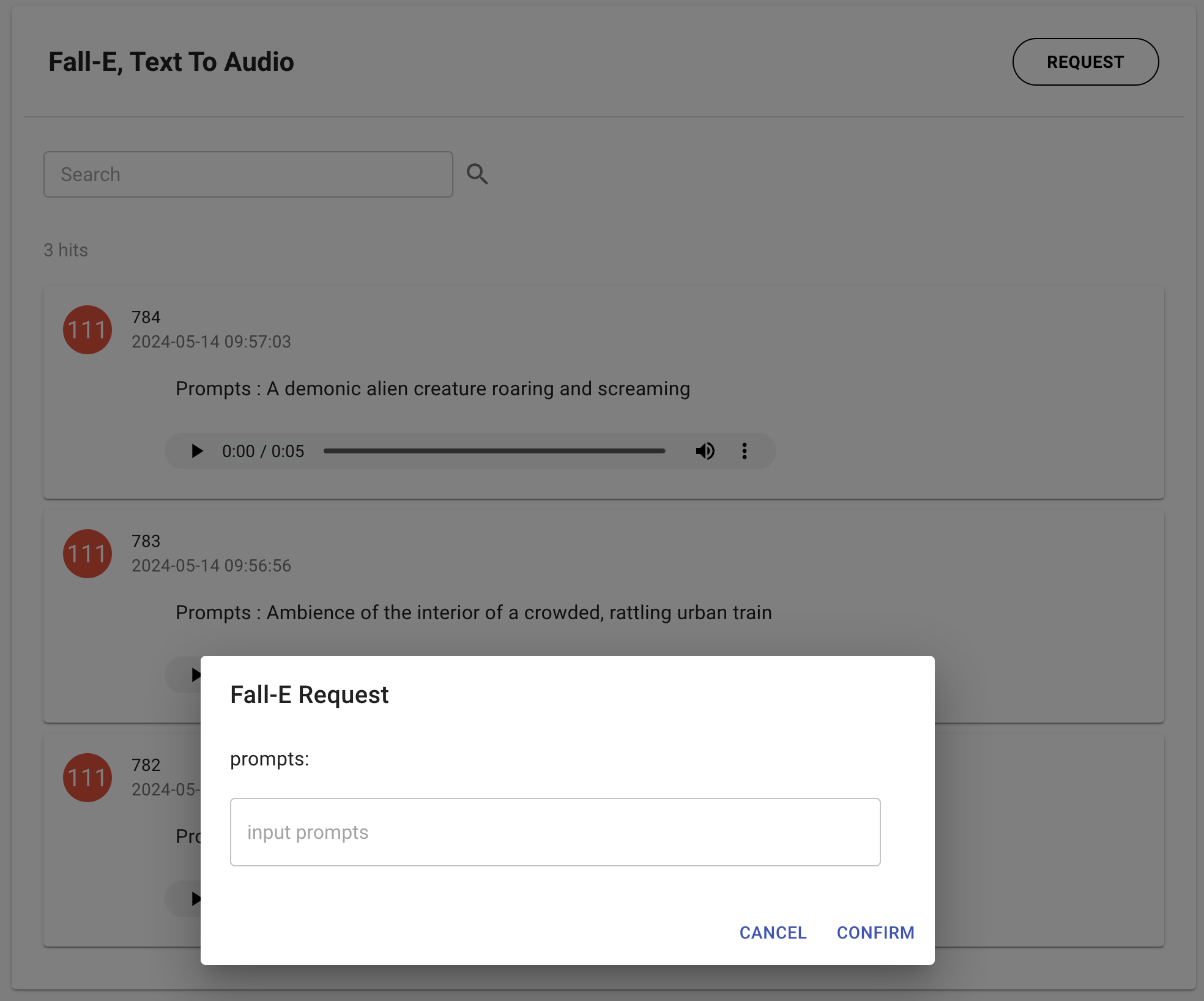
Text to Audio 생성 화면
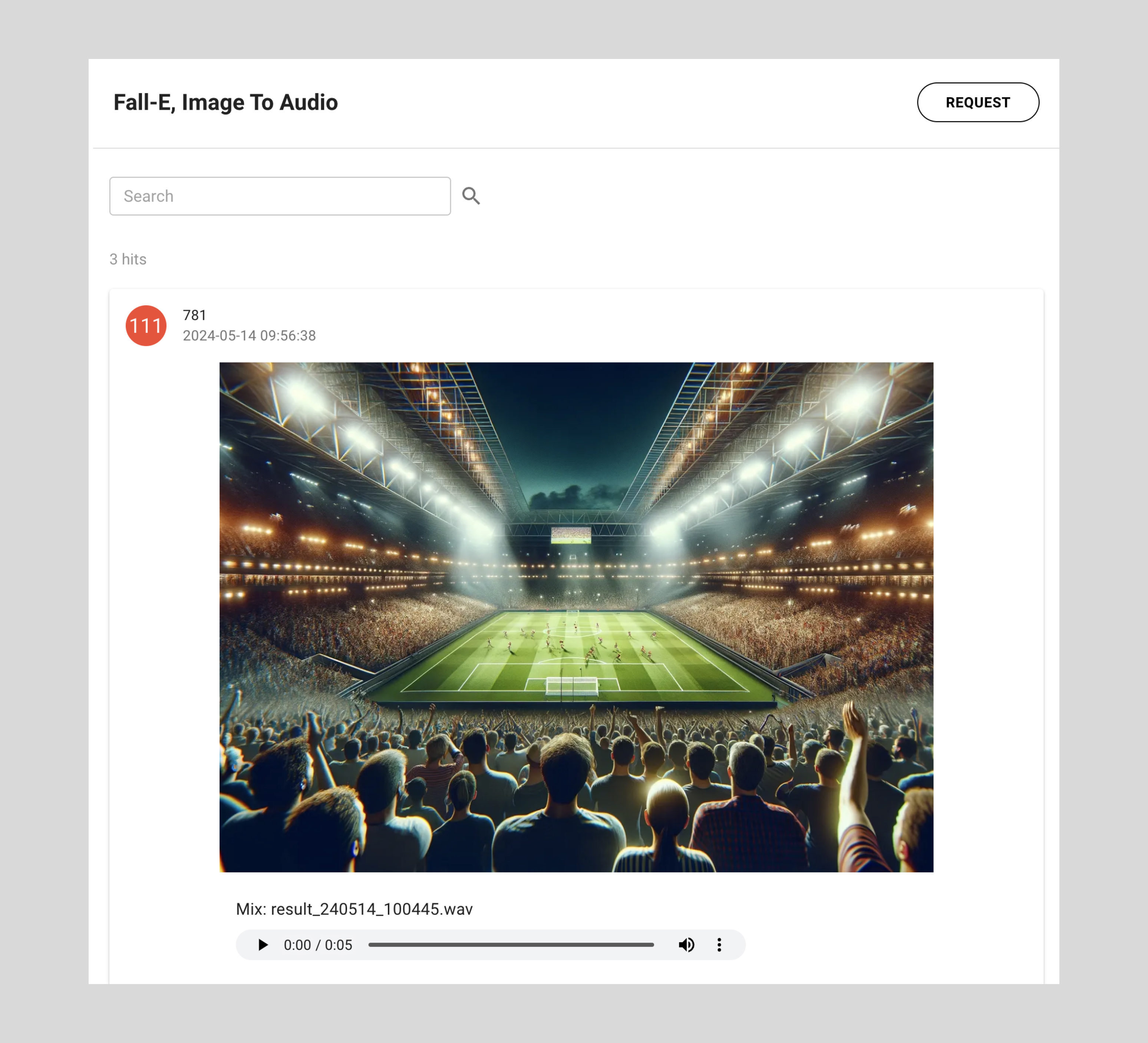
Image to Audio 생성화면
이 데모 페이지를 경험한 AI타임즈 장세민 기자님의 체험기를 공유드리고자 합니다.
이번 체험기를 통해 가우디오랩이 불러올 미래를 함께 상상해보시기를 권해드려요.
그럼 이하 전문으로 확인하시죠!
-
[체험기] 나델라가 감탄한 AI 생성 효과음,어디까지 진화했을까
2024-05-26
음성 인공지능(AI) 전문 가우디오랩(대표 오현오)이 소리(효과음) 생성 AI를 사용해 볼 수 있는 클로즈드 데모(Closed Demo) 사이트를 공개했다고 최근 밝혔다.
가우디오랩의 대표 솔루션 '폴리(FALL-E)'는 지난 1월 미국 라스베이거스 CES 현장에서부터 글로벌 업계의 주목을 받은 바 있다. 사티아 나델라 MS CEO가 부스를 찾아 "이제 진짜 AI가 생성한 소리냐"라고 놀랐던 그 제품이다.
폴리는 텍스트를 넘어 이미지도 입력할 수 있는 '멀티모달 AI'로, 해외 기업보다 앞선 기술을 갖췄다. 최근에는 프론트엔드 개발까지 완료, 클로즈드 데모 공개를 통해 한정된 사용자를 대상으로 테스트 중이다.
AI타임스도 테스트에 참여, 클로즈드 데모 사이트에 접속해 몇가지 기준에 따라 소리를 만들어 보기로 했다.
먼저 폴리의 기본 기능을 테스트하기 위해 텍스트를 입력해 봤다. 현재는 영어 프롬프트만 지원한다.
첫번째 프롬프트는 '흙길에서 속도를 내는 오래된 트럭(An old pickup truck accelerating on a dirt road)'이다. 생성된 사운드는 바퀴가 굴러가는 느낌을 잘 구현했다. 조금 더 거친 소리를 살리는 것도 방법일 듯하다.
두번째는 '번잡하고 덜컹거리는 도심의 열차(Ambience of the interior of a crowded, rattling urban train)'다. 이건 실제 소리라고 해도 과언이 아닐 정도로 리얼했다.
다음은 '비명을 지르는 악마 같은 외계 생명체(A demonic alien creature roaring and screaming)'로, 소리를 재생하자마자 소름이 돋을 정도였다. 미스터리, 스릴러, 호러 등의 장르에서 유용한 기술이라는 생각이 들었다.
'거칠게 닫히는 문(a door closed violently)' '비가 온 뒤 진흙을 밟는 소리(stepping on mud after rainning)' '유령 소리(ghost sound)' '살인자가 누군가를 추격하며 하하하- 웃는 소리(HAHAHA- sound of murderer chasing someone)' 등을 차례로 생성해 봤다. 모두 기대 이상의 결과가 나왔다.
단 하나 아쉬운 점은 대사나 목소리를 구현할 수는 없었다는 점이다. '두려움에 가득 차 "누구세요?"라고 묻는 소리("Who is that?" voice with fear)'의 경우는 결과물이 나오지 않았다.
가우디오랩 관계자는 "폴리는 음성(목소리)이나 음악을 대상으로 개발되지는 않았다"라며 "음성, 음악, 효과음 중 효과음에 집중해서 만들어진 것"이라고 설명했다. 이어 "재채기나 기침소리와 같은 비언어적 소리는 포함하지만, 언어적인 것들은 다른 많은 기술, 즉 TTS(텍스트 음성 변환) 등을 통해서 만들어야 한다"라고 전했다.
그래도 놀라운 것은 단순히 소리를 만들어내는 것을 넘어, '하나의 스토리'를 상상할 수 있을 만큼 퀄리티 있는 효과음을 도출한다는 것이다.
특히 누구나 쉽게 사용할 수 있는 것이 장점으로 보였다. 이미지 생성 AI처럼 아주 상세하거나 특정한 표현 없이도, 일상적인 단어 몇개로 그럴듯한 소리를 만들어 낼 수 있었다.
그렇다면 '아주 미묘한 차이'까지도 소리로 표현할 수 있을까.
이를 확인하기 위해 나이와 감정, 사물의 질감, 소리의 거리, 규모 등 프롬프트마다 약간의 차별점을 부여해 봤다. 먼저 '어린아이의 울음소리'를 통해 나이 차를 어떻게 표현하는지 테스트했다.
첫번째로 '시험을 망치고 울고 있는 아이(A child is crying after ruining the test)'를 입력했다. 하지만 생각한 결과물은 아니었다. 학교 시험을 치르기에는 지나치게 어린 느낌이었다. 이에 구체적인 연령 설정을 추가했다.
'시험을 망친 뒤 울고 있는 13살의 남자아이(A 13-year-old boy student is crying after ruining the test)'를 입력하자 일전보다 훨씬 성숙한 목소리를 생성해 줬다. 텍스트만으로 나이 조절이 가능했다.
사물의 질감의 경우 초콜릿과 꿀을 비교했다. 공통적인 수식어는 '끈적거리는(sticky)'이다. 강철과 꿀을 비교하라면 확실하게 다른 소리를 만들겠지만, 비슷한 점도를 다른 소리로 표현하기란 쉽지 않을 듯 보였다.
그러나 결과를 확인하고 놀랄 수밖에 없었다. 폴리는 재료 간의 차이를 정확히 잡아냈다.
감정은 '개가 짖는 소리(bark)'를 이용했다. 한쪽은 분노와 경계심을 가지고 짖는 소리, 나머지 한쪽은 산책을 가고 싶어 칭얼거리며 짖는 강아지다. 이번에도 명확한 차이가 드러났다. 감정 표현에도 무리가 없었다.
마지막으로 거리와 규모를 가늠하기 위해 '좀비의 으르렁거리는 소리(growl)'를 이용했다. 즉 '가까이에서 좀비 하나가 으르렁거리는 소리' '먼 거리에서 좀비 여럿이 으르렁거리는 소리' '가까이에서 좀비 여럿이 으르렁거리는 소리' 등으로 구분했다.
규모의 경우 하나로 설정했을 때 훨씬 섬세한 사운드 표현이 나타났다. 흥미로운 것은 거리의 차이였다. 똑같은 좀비 집단이더라도 멀리 있는 경우 '벽 하나가 가로막고 있는 듯' 희미한 소리로 표현됐다.
마지막은 가장 궁금했던 '이미지 입력'이었다. 이는 가우디오랩의 차별점이자, 최종 목표를 위한 시작점이기도 하다. 영상 자체를 입력해 사운드를 생성할 수 있다면, 영화 작업에 획기적인 시간 단축을 가져올 수 있기 때문이다.
하지만 기술적으로 어렵기도 하다. 텍스트의 경우 입력자의 의도가 명확하게 드러나지만, 이미지는 AI가 분석하는 부분이 훨씬 많아지기 때문이다. 즉 앞서 테스트한 감정이나 거리, 규모, 질감, 연령 등을 전부 AI가 다시 분석하고 계산해야 한다.
테스트 결과 가장 흥미로웠던 것은 AI가 소리를 하나만 내놓지 않았다는 점이었다.
폴리는 사진에 포함된 여러 개체와 상황을 반영해 최대 3가지 소리를 따로 제시하고, 마지막으로 '통합본'을 제시하는 등 모두 4가지 소리를 들려 줬다.
예를 들면 두 사람이 싸우는 장면에서는 ▲옷이 부스럭거리는 소리 ▲바닥에 부딪히는 소리 ▲창문이 깨지는 소리 등이 생성됐다.
이미지 입력에는 '생성 이미지'와 '영화 공식 스틸 컷' 두가지를 사용했다.
라스코AI를 이용해 생성한 만화 그림체의 사진을 입력하자, 폴리는 모든 개체를 정확히 인식하지는 못했다. 소녀와 개가 놀고 있는 장면에서 강아지가 짖는 소리는 생성했지만, 소녀의 웃음소리는 나오지 않았다. 아무래도 그림은 명확하지 않은 부분이 있다는 점 때문인듯 싶었다.
그래서 이번에는 실사를 입력했다. '존 윅' '트랜스포머' '터미네이터' '분노의 질주' 등 다소 강렬한 영화 이미지를 사용했다.
이번에는 모든 개체를 인식했지만, 실제 영화 속 효과음만큼 강렬한 소리는 나오지는 않았다. 아무래도 스틸 컷 하나로 영상 전체의 강렬함을 전달하기는 어려웄을 듯 싶었다. 영화의 맥락을 인식했다면, 더 강한 효과음을 생성했을 수도 있겠다는 생각이 들었다.
이 외에도 유니콘을 타고 있는 모습, 소가 일하고 있는 모습 등 '소리를 명확히 유추할 수 없는 이미지'를 이용했을 때도 그럴듯한 결과물을 내놓았다.
영상을 확인하면 알 수 있듯, 이번 테스트에서는 전반적으로 기대 이상의 결과를 확인했다. 나델라 CEO가 이번 버전을 확인한다면, 더 놀랄 것이 틀림없을 것 같았다.
가우디오랩은 누구나 원하는 사운드를 쉽게 만들 수 있도록 노력하고 있다고 밝혔디. 관계자는 "기업 비전에 맞게 비전문가도 소리 생성AI를 체험해 볼 수 있다는 점에서 이번 테스트는 큰 의미가 있다"라고 전했다.
이제까지 남들보다 앞선 높은 퀄리티의 기술을 개발해온 만큼, 앞으로 멀티모달 영역이 영상까지 확대된다면 "앞으로 모든 영화와 영상에는 가우디오랩의 기술이 들어갈 것"이라는 말이 현실이 될 수도 있겠다는 생각이 들었다.
장세민 기자 semim99@aitimes.com
출처 : AI타임스(![]() AI타임스 )
AI타임스 )


다양한 디바이스와 플랫폼에 적용 가능한 오디오 기술을 만나 보세요
