사운드 엔지니어가 소개하는 Gaudio Studio 사용법, 음원분리 꿀팁
안녕하세요, 가우디오랩 사운드엔지니어 브라이트입니다!
요즘 많은 분야에서 AI를 활용하여 생산성을 높이고 있죠. 여러분들도 한 번쯤은 AI 툴을 접해본 적이 있을 것 같은데요. 혹시 오디오 AI 회사의 사운드 엔지니어는 AI를 어떻게 활용하고 있을지 궁금하지 않으신가요?
저는 어릴 적, MR 제작과 믹싱 연습을 위해 힘들게 구글링을 하던 기억이 있습니다. 겨우 찾아낸 방법으로 직접 MR을 분리해내거나, 학습 자료로 공개된 멀티 트랙을 다운 받아 믹싱 연습을 했던 때가 기억이 새록새록 나네요. 지금은 간단한 제작 과정도 과거에는 일일이 수작업을 요구하다 보니, 이렇게 어렵게 완성한 작업물도 퀄리티가 영 불만족스러웠던 경우가 많았답니다.😭
그런데 이제는 AI의 시대가 도래하면서 이런 수고로움은 다 옛 일이 되었어요! 특히 AI로 음원을 분리해 주는 기술이 상용화되면서 오디오 산업에도 많은 작업들이 참 간편해졌습니다. 사운드엔지니어로서, 오로지 창작에만 몰두할 수 있는 좋은 시대가 온 게 아닐까라고 생각해요.
오늘은 그중에서도 제가 가장 많이 사용하는 GAUDIO STUDIO의 여러 꿀팁들을 소개해드리려 합니다. 여러 AI 음원 분리 서비스 중 최고의 성능을 자랑하고 있어 정말 다양하게 사용하고 있는데요, 천천히 따라오시다 보면 여러분들도 수준급의 사운드 엔지니어가 되어있지 않을까요 😎
🍯 꿀팁 1 - MR 만들기
1단계 - 보컬 분리하기
GAUDIO STUDIO에서 보컬과 음악을 어떻게 분리하나요?
정말 자주 들어오는 질문 중 하나인데요. 장기자랑 / 축가 / 이벤트 등을 위한 MR 제작은 GAUDIO STUDIO를 이용하는 많은 분들의 주 사용 목적이 아닐까 싶어요.
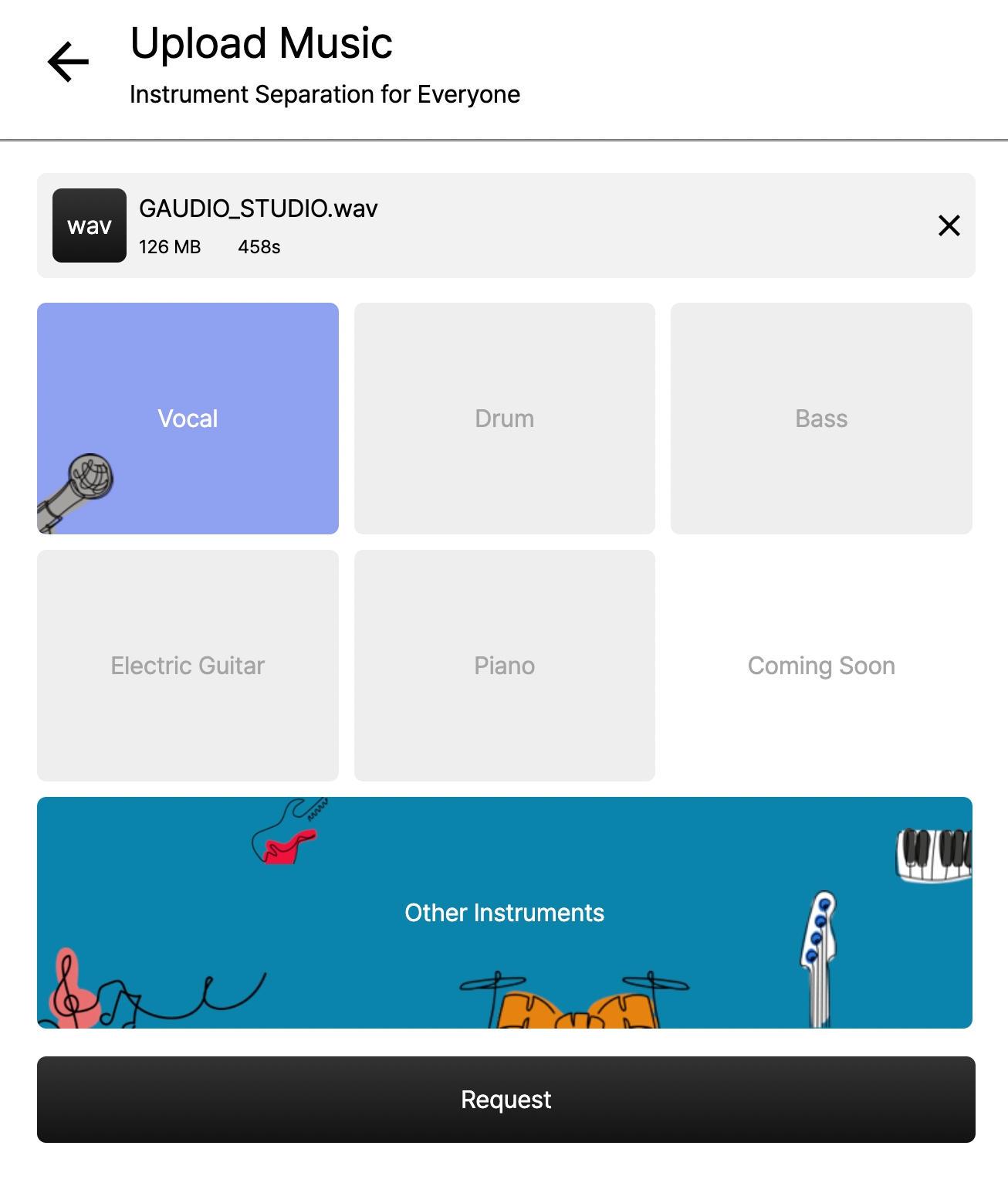
'보컬'과 '그 외 악기들'만 선택한 화면
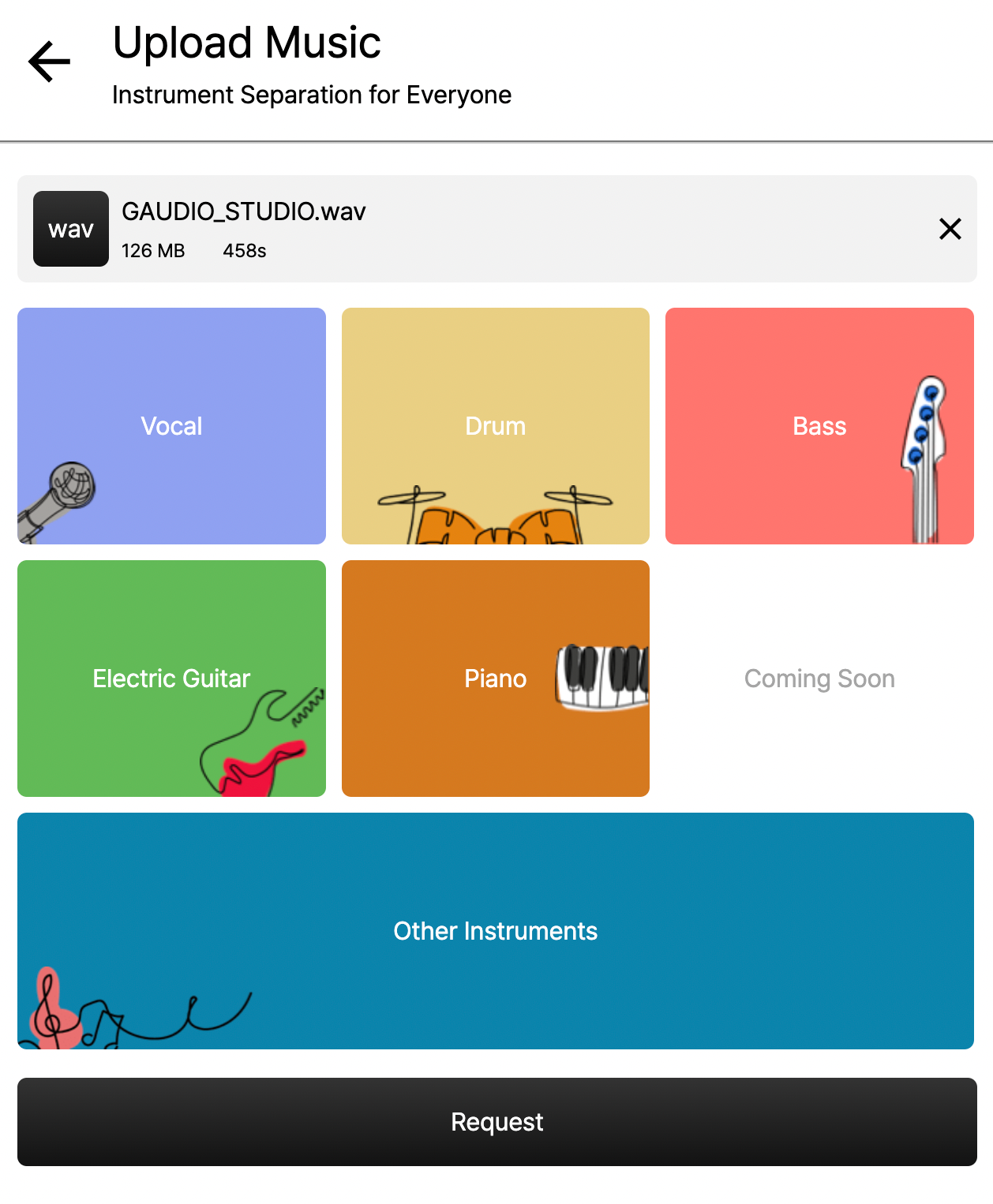
모든 악기를 선택한 화면
GAUDIO STUDIO에서는 원하는 악기를 선택하여 음원을 분리할 수 있습니다 (보컬, 드럼, 베이스, 전자 기타, 피아노, 그 외 악기들). 여기서 보컬만 선택하여 분리해낸다면 MR을 제작할 수 있겠죠?
나머지는 AI가 알아서 처리해주기 때문에 이렇게 간단한 클릭 몇 번 만으로도 MR을 쉽게 만들 수 있답니다!
2단계 - 키(Key) 업 / 다운
MR을 나에게 맞는 키로 맞출 수 있나요?
우선 기존에 사용하던 음원 편집 프로그램이 없다면, Audacity를 추천드려요. 무료 프로그램이지만, 다양한 기능들이 숨겨져 있어 저도 학생 시절에 무척이나 많이 사용했던 프로그램이랍니다.
준비가 다 되셨나요? 이제 한번 천천히 따라 해볼게요!
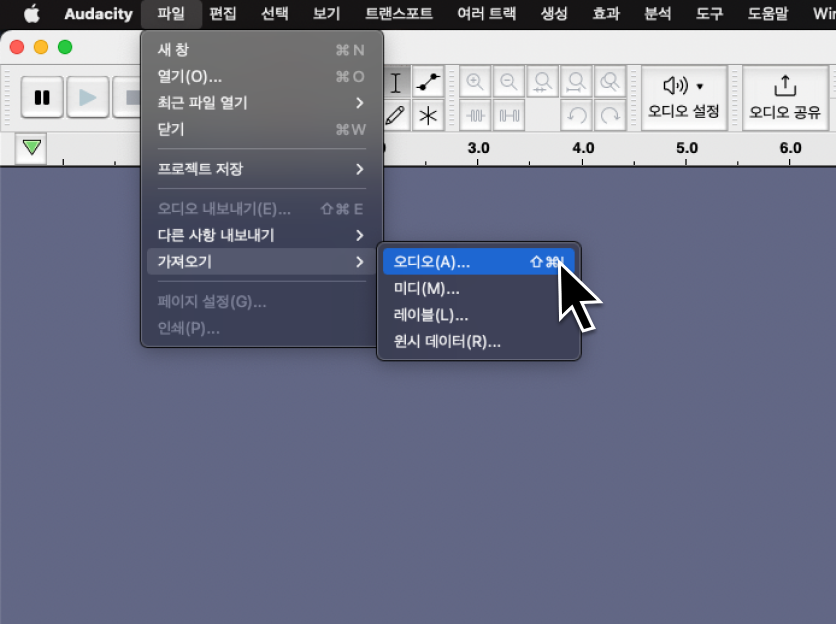
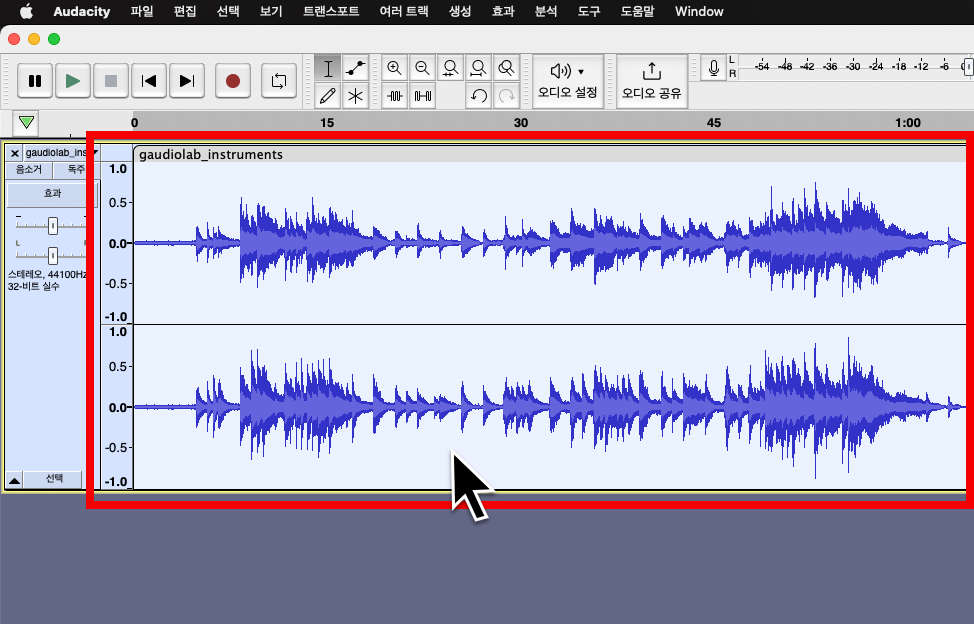
먼저 상단 [파일] → [가져오기] → [오디오]를 눌러 원하는 음원을 불러온 뒤, 불러온 파일을 더블클릭 하여 전체 선택합니다.
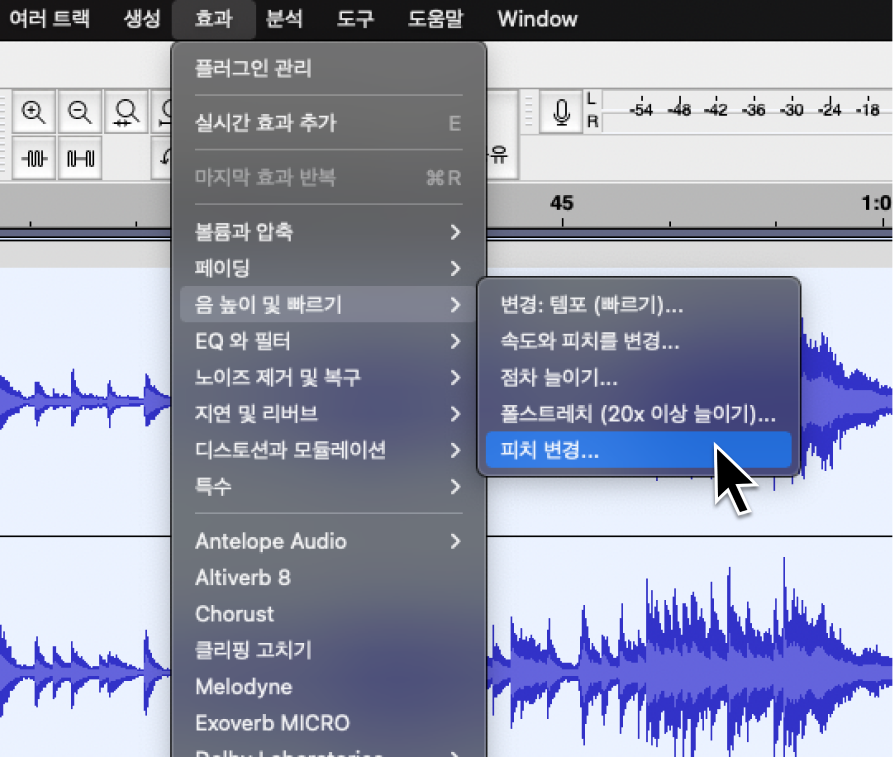
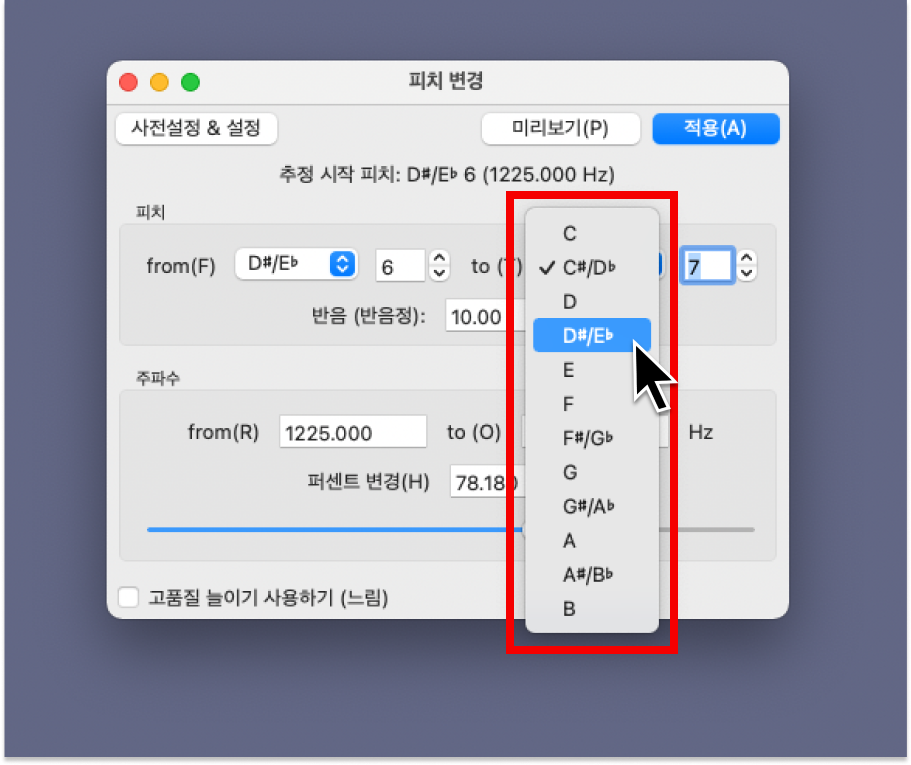
그리고 [효과] → [음 높이 및 빠르기] → [피치 변경]으로 들어가서 키를 조정하면 끝이에요!
미세조정도 가능하니 몇 번 테스트해 보며 원하는 피치로 바꿔보세요.
여기까지 잘 따라오신 분들, 그런데 뭔가 이질감이 들지 않나요? 아니면 남들과는 다른 고품질 MR을 만들고 싶지는 않으신가요?
우리가 평소 자주 놓치고 있는 한 가지 사실이 있습니다. 바로 드럼에는 음정이 없다는 것!
이 때문에 드럼 트랙이 포함된 채로 키를 변경하게 되면, 드럼 비트의 키도 함께 바뀌게 되어 완성도에 영향을 주게 되는거죠.
😎 자! 이제 여기서 비법을 하나 알려드릴게요. 이번에는 드럼 트랙만 제외하고 나머지 악기들의 키를 조정한 뒤, 드럼과 다시 합쳐보세요. 이제 그 수상한 이질감이 사라졌을 겁니다!
3단계 - 활용해 보기
그래서 이걸로 무엇을 더 할 수 있나요?
MR 분리에 이어, 내 마음대로 키까지 변경할 수 있다면, 이런 콘텐츠도 만들어볼 수 있답니다.
느낌 오시죠? 이렇게 서로 보컬 키가 다른 가수들의 듀엣도 만들어 볼 수 있어요!
여기에 분리한 목소리를 Voice Conversion AI 학습 모델을 통해 재가공한다면, 요즘 유행하는 AI 커버 콘텐츠도 만들 수 있습니다. 이때 당연히 분리된 목소리의 퀄리티가 좋을수록 학습된 결과물이 좋기 때문에 GAUDIO STUDIO를 많이 사용하고 있다는 이야기를 들었어요.👀
내 최애가 부르는 다른 가수의 노래, 궁금하지 않으신가요?
😎 이렇게 GAUDIO STUDIO를 이용한 활용법은 무궁무진하답니다.
🍯 꿀팁 2 - 이미 녹음한 음원에서 특정 트랙 조절하기
이번에는 여러분들이 일상에서 한번쯤 마주 할 수 있는 상황에서 GAUDIO STUDIO를 활용할 수 있는 예시를 보여드릴게요.
상황 1 - 정말 훌륭한 합주를 마쳤는데, 드럼소리만 너무 커요!
이런 경우 드럼 트랙만을 분리해서 음량을 조절해준다면 다른 악기들을 살릴 수 있겠죠? 같은 원리로 공연장 직캠 영상에서 지나치게 쿵쿵거리는 비트를 줄여 아티스트의 목소리를 더욱 살릴 수 있답니다.
도저히 분리가 되지 않을 것 같던 합주실 녹음본도, 살릴 수 없을 것만 같았던 직캠영상도, 이제는 훌륭하게 믹싱 해서 업로드해보세요!
상황 2. 카페에서 브이로그를 촬영했는데, 저작권 등록된 음악이 함께 녹음되었어요!
유튜브에 올릴 브이로그를 찍었는데 카페 배경 음악이 함께 녹음되었다면, 저작권 침해 요소로 감지되어 수익 창출이 제한될 수 있어요. 아마 그동안은 무작정 볼륨을 낮추거나 목소리를 올렸을 거예요. 그래도 해결이 안 되면 소리를 전부 날리고 나레이션을 녹음했을 것이구요.
😎 이제는 그러지 말고 내 목소리만 분리해서 원하지 않은 음악을 깔끔하게 제거해 보세요.
GAUDIO STUDIO만 있다면 더이상 예상치 못한 저작권 문제로 고통받지 않아도 된답니다!
AI 음원분리를 이용한 무궁무진한 활용 사례, 잘 보셨나요?
옛날에는 하고 싶어도 하지 못했거나, 하려면 엄청난 수고를 감수해야 했던 작업들을 이제는 너무 쉽게 하고 있다는 생각이 들면서 문득 깜짝깜짝 놀라곤 합니다.
여러분들도 마법 같은 GAUDIO STUDIO를 통해 개성 있는 콘텐츠를 만들고 즐겨보는 건 어떨까요?
멀지 않은 미래에, 스테레오 파일을 넣으면 모든 트랙 스템이 깔끔하게 분리가 될 그날까지 GAUDIO STUDIO 고도화는 계속될 예정입니다.
앞으로 많은 관심과 이용 부탁드려요~

다양한 디바이스와 플랫폼에 적용 가능한 오디오 기술을 만나 보세요
